 Home
Home Products
Products Resources
Resources Solutions
Solutions Pricing
Pricing Company
Company Find Us
Find UsAI Agent Token Cost Optimization Guide
AI Agent token bills exceeding expectations? Most teams only account for "input + output," missing hidden costs from system prompts, conversation hist

Summary
AI Agent token bills exceeding expectations? Most teams only account for "input + output," missing hidden costs from system prompts, conversation history, and RAG context injection. This guide from Tencent Cloud ADP covers three proven strategies: intent routing, retrieval optimization, and tiered models.
Build Enterprise AI Agents — Tencent Cloud ADP, free trial for the first month
This guide covers:
- Token consumption composition across Agent pipeline stages, including hidden costs
- How intent routing diverts simple requests away from heavy processing pipelines
- How RAG retrieval precision optimization reduces unnecessary context injection
- How tiered model strategies cut inference costs while maintaining quality
You'll learn: How to build an observable, quantifiable token cost governance methodology.
Why Token Costs Spiral Out of Control
The Hidden Consumption Problem
Most teams estimate AI Agent costs by multiplying "tokens per call × request volume." But in production, a single user request triggers far more token consumption than meets the eye:
| Consumption Stage | Typical Token Volume | Incurred on Every Call? |
|---|---|---|
| Raw user input | 20-200 | Yes |
| System prompt | 500-3,000 | Yes, carried on every call |
| Conversation history | Turn N ≈ N × single-turn cost | Accumulates in multi-turn scenarios |
| RAG retrieval results | 500-5,000 | In knowledge Q&A scenarios |
| Model output | 200-1,000 | Yes |
A user question that appears to cost 200 tokens may trigger a full pipeline consuming 3,000-8,000 tokens. At tens or hundreds of thousands of daily requests, this gap compounds dramatically.

Three Common Cost Problems
- Budget deviation: Initial estimates ignore multi-turn accumulation, system prompts, and retrieval injection, leading to bills far exceeding projections after launch
- Cost unobservability: No visibility into which intents or stages consume the most tokens, making optimization impossible
- Quality vs. cost deadlock: Downgrading models risks accuracy; maintaining them leaves costs uncontrolled
How Tokens Flow Through the Agent Pipeline
To optimize costs, you need to understand how tokens are consumed at each stage of the Agent processing pipeline.
Anatomy of a Single Request
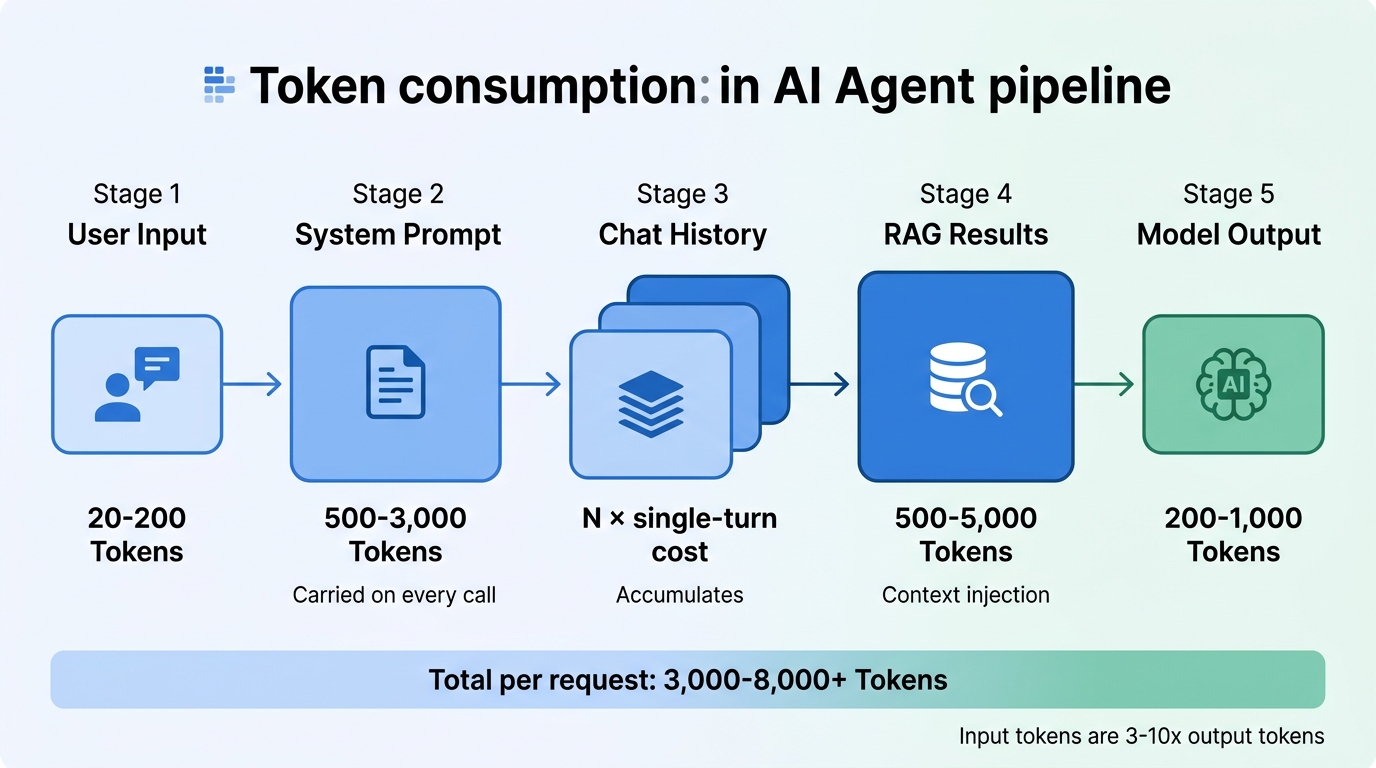
A typical enterprise AI Agent processes each user request through multiple stages:
| Stage | Purpose | Token Consumption Pattern |
|---|---|---|
| Intent recognition | Classify user request into appropriate business scenario | Input: system prompt + user input; Output: intent label (200-500 tokens) |
| Parameter extraction | Extract structured parameters from natural language | Input: extraction rules + user input; Output: JSON parameters (100-300 tokens) |
| Knowledge retrieval | Retrieve relevant document segments from vector database | Retrieval itself doesn't consume inference tokens, but results injected into context increase subsequent input tokens |
| Response generation | Generate final response based on context | Input: system prompt + conversation history + retrieval results; Output: response text |
| Quality validation (optional) | Check response accuracy and compliance | Additional model call, 100-500 tokens |
Key insight: In a single request, input tokens are typically 3-10x output tokens. The core of cost optimization lies in reducing input-side redundancy — particularly system prompts and retrieval injection.
Three Core Optimization Strategies
Strategy 1: Intent Routing — Fast-Track Simple Requests
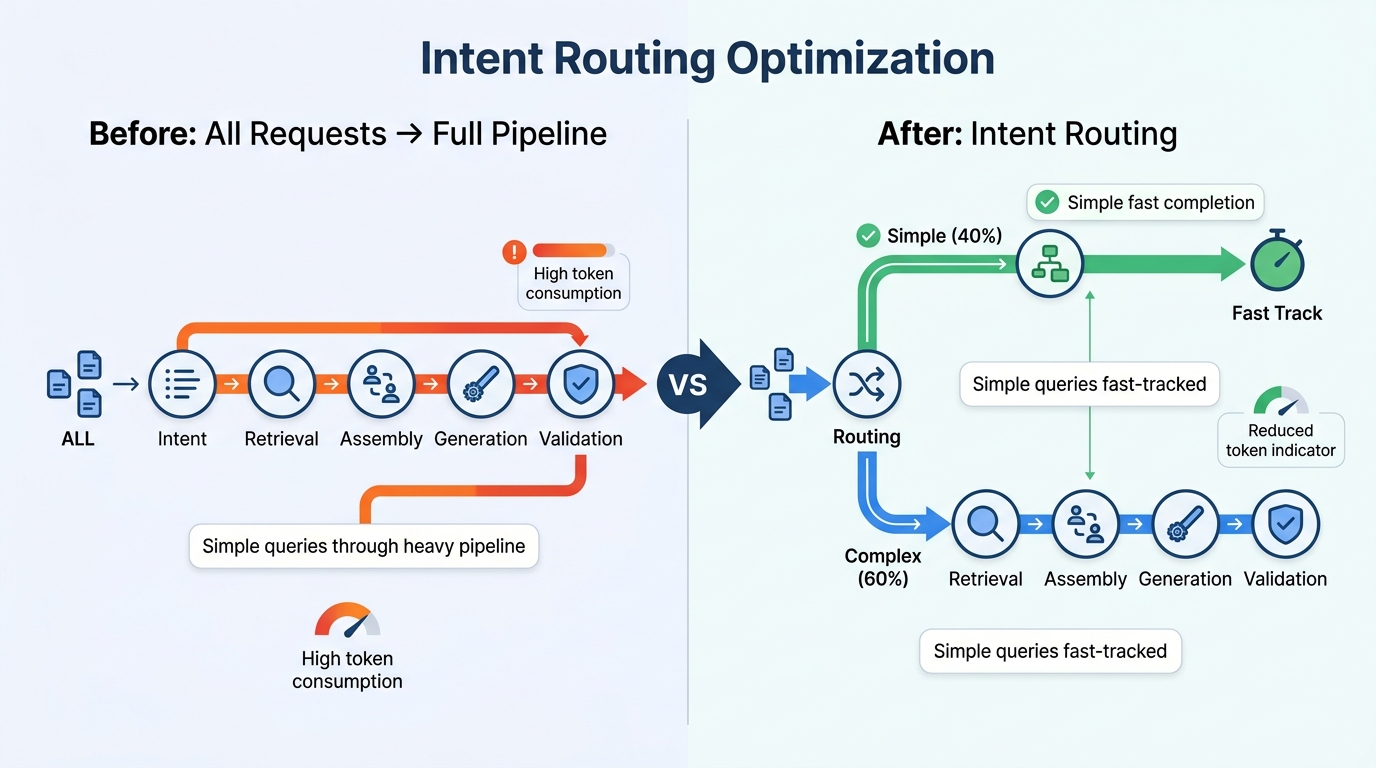
Problem: Many Agent architectures treat all requests equally, sending everything through the full "intent classification → retrieval → generation → validation" pipeline — even when the user is asking "where's my order?"
Solution: Add a lightweight intent classification step before requests enter the full pipeline.
Tencent Cloud ADP's intent recognition engine supports global intent classification and parameter fallback:
- Lightweight model classification: Use cost-effective models for intent classification, consuming only 200-500 tokens per call
- Route splitting: Simple queries (status checks, FAQs) are handled directly via tool calls or fixed responses, bypassing the full pipeline
- Parameter fallback: When user input lacks required parameters, automatically prompt for clarification rather than blindly triggering retrieval and generation
How the math works: A full "retrieval + generation" pipeline consumes 3,000-8,000 tokens. If 30-50% of requests are simple queries, routing them away from the heavy pipeline reduces their token consumption by 80%+. Even if intent classification costs 300 tokens per call, intercepting just 10% of simple requests makes the investment pay for itself.
Strategy 2: RAG Retrieval Precision — Reduce Unnecessary Context Injection
RAG is a core capability for enterprise AI Agents, but it's also the largest cost variable. More retrieved document segments mean more tokens injected into model context, and costs scale linearly.
Optimization comparison:
| Retrieval Parameter | Common Default | Optimization | Token Impact |
|---|---|---|---|
| Documents returned | Top 10 | Top 3-5 | 50-70% reduction in context injection |
| Max document length | 1,000 tokens | 500 tokens | 50% reduction per document |
| Reranking | Not enabled | Enabled | Higher precision; fewer documents needed at same accuracy |
| Chunking strategy | Fixed 500-char splits | Semantic chunking (200-300 tokens) | Reduced irrelevant information injection |
Specific techniques:
- Small chunks + reranking: Split documents into smaller semantic chunks (200-300 tokens), retrieve Top 10 candidates, then use a reranking model to select the Top 3-5 for context injection
- Pre-retrieval metadata filtering: Filter the candidate set by metadata (department, document type, date range) before vector retrieval
- Query rewriting: Use a lightweight model to rewrite colloquial user queries into precise search terms, improving first-pass retrieval hit rates
Tencent Cloud ADP's knowledge retrieval module supports 28+ document formats, 200MB per file, and built-in reranking capabilities — these parameters can be configured directly at the platform level.
Strategy 3: Tiered Models — Match Model to Task Complexity
This delivers the most significant cost reduction. The core idea: not every task needs the most powerful (and expensive) model.
| Task Type | Complexity | Recommended Model Tier | Cost Reference |
|---|---|---|---|
| Intent classification | Low | Lightweight (e.g., GPT-4o-mini) | $0.15/MTok input |
| Parameter extraction | Low | Lightweight | $0.15/MTok input |
| Simple Q&A | Medium | Mid-tier (e.g., Claude Haiku) | $1.00/MTok input |
| Complex reasoning | High | Flagship (e.g., Claude Sonnet) | $3.00/MTok input |
Key principle: Don't choose models by intuition — use evaluation data. Tencent Cloud ADP's application evaluation suite provides "comparative evaluation" — running the same test cases through flagship and lightweight models to quantify quality differences. If the lightweight model's accuracy is only 2-3% lower but costs 10x less, the choice is clear.
Blended cost example:
Assuming 100K daily requests, distributed as:
- Simple queries 40% → lightweight model: 40,000 × $0.001 = $40
- Standard Q&A 45% → mid-tier model: 45,000 × $0.005 = $225
- Complex reasoning 15% → flagship model: 15,000 × $0.030 = $450
Total cost: $715/day
vs. all requests on flagship model: 100,000 × $0.030 = $3,000/day
Savings: ~76%
Optimization in Action
Using a "shipment tracking" scenario to illustrate before-and-after token consumption.
User input: "Can you check where shipment SF1234567890 is?"
Before Optimization (full pipeline, single flagship model)
| Step | Model | Input Tokens | Output Tokens |
|---|---|---|---|
| Intent classification | Flagship | 1,200 | 150 |
| Parameter extraction | Flagship | 1,500 | 80 |
| Knowledge retrieval | Embedding model | 300 | — |
| Context assembly | — | 3,500 (retrieval results) | — |
| Response generation | Flagship | 5,200 | 200 |
| Total | ~11,700 | ~430 |
After Optimization (intent routing + tiered models + retrieval reduction)
| Step | Model | Input Tokens | Output Tokens |
|---|---|---|---|
| Intent classification | Lightweight | 800 | 120 |
| Parameter extraction | Lightweight | 1,000 | 60 |
| Structured query | API call (no model) | — | — |
| Response generation | Mid-tier | 1,200 | 150 |
| Total | ~3,000 | ~330 |
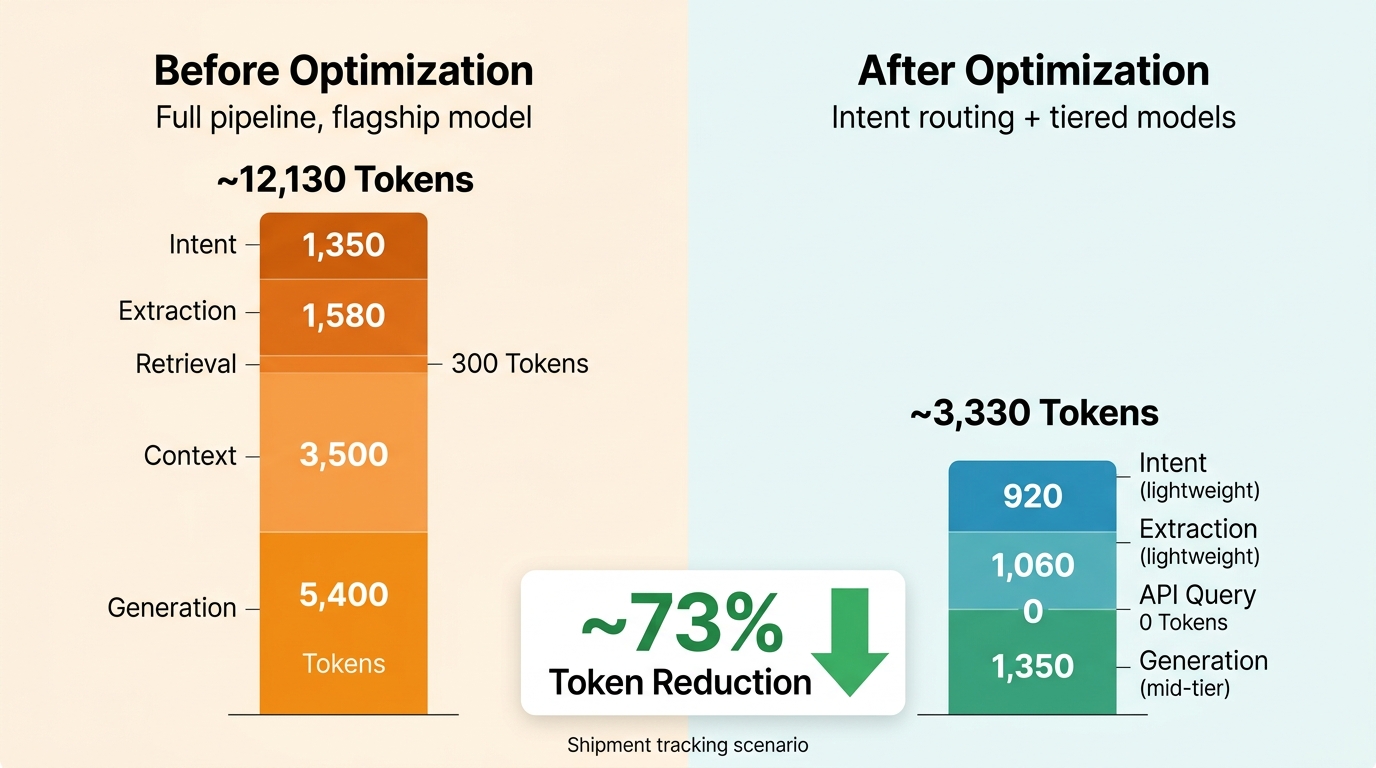
"Shipment tracking" is a simple query — intent routing identifies it and goes straight to a structured API call, skipping the RAG retrieval stage entirely.
A Quantifiable Optimization Framework
Token cost optimization isn't a one-time action — it requires continuous monitoring and iteration.
Three Dimensions of Cost Observability
| Dimension | Metrics to Monitor | Optimization Action |
|---|---|---|
| Intent | Average token consumption per intent, request distribution | Identify Top 10 high-consumption intents for priority optimization |
| Stage | Token share by stage (classification/retrieval/generation) | Locate consumption hotspots for targeted adjustments |
| Model | Call count, success rate, and cost share per model | Validate tiered strategy effectiveness, continuously adjust allocation |
Implementation Roadmap
- Establish baselines: Measure token consumption per intent before launch
- Deploy intent routing: Divert simple requests away from the heavy pipeline first
- Tune retrieval: Adjust chunking strategy and Top-K parameters; use reranking instead of "return more documents"
- Layer models: Use comparative evaluation to validate lightweight models per intent, then gradually substitute
- Monitor continuously: Build token consumption dashboards across intent/stage/model dimensions
Industry Applicability
Token cost optimization applies to any enterprise deploying AI Agents, especially scenarios with these characteristics:
| Scenario Profile | Optimization Focus | Expected Effect |
|---|---|---|
| High request volume, many simple queries | Intent routing | 80%+ token reduction for simple queries |
| Large knowledge base, frequent retrieval | RAG precision optimization | 50-70% reduction in context injection tokens |
| Diverse task types with varying complexity | Tiered model strategy | 50-70% reduction in blended inference cost |
| Frequent multi-turn conversations | Conversation history compression + routing | Significant reduction in accumulated tokens |
FAQ
Q1: Doesn't intent routing itself consume tokens? Could savings be less than the overhead?
Unlikely. Intent classification with a lightweight model consumes just 200-500 tokens per call. A full "retrieval + generation" pipeline consumes 3,000-8,000 tokens. As long as routing intercepts more than 10% of simple requests, the investment pays for itself.
Q2: Will model downgrading hurt response quality?
The key is using data rather than intuition. Use ADP's comparative evaluation feature to validate lightweight model performance for each intent separately. If a specific intent's accuracy drops more than 5% after downgrading, keep the flagship model for that intent.
Q3: Is there a significant quality difference between RAG returning Top 3 vs. Top 10?
It depends on chunking strategy and reranking quality. In practice, Top 3 + reranking typically matches or exceeds Top 10 (without reranking) in accuracy — because noise is reduced. The prerequisite is reasonable chunk sizes (200-300 token semantic chunks).
Q4: At what token volume should I start optimizing costs?
If daily token consumption exceeds 1 million (monthly inference cost ~$3,000-15,000), systematic optimization is worthwhile. At 10 million+ daily tokens, optimization is a necessity.
Q5: How do I build continuous token cost monitoring?
Build a consumption dashboard across three dimensions: "intent → stage → model." Focus on the Top 10 highest-consuming intents, consumption trends per intent, and cross-analysis of call count vs. success rate.
Q6: Beyond inference tokens, what other hidden costs are commonly overlooked?
Watch for: knowledge base maintenance costs (document updates, chunk rebuilding, index refresh), human review costs (manual intervention for edge cases), and latency costs (excessive pipeline length degrading user experience).
Conclusion: Token Optimization Is About Precision
Enterprise AI Agent cost optimization is fundamentally not about "saving money" — it's about precision — spending every token where it counts.
Three key actions:
- Precise routing: Use lightweight models for intent classification, fast-tracking simple requests
- Precise retrieval: Small chunks + reranking to reduce noisy context injection
- Precise matching: Use different model tiers for different task complexities, guided by evaluation data
The greatest value of this methodology isn't any single technique — it's establishing an observable, quantifiable, and iteratively improvable cost governance framework.
Ready to get started?
→ Try Tencent Cloud ADP — Knowledge base, workflow engine, and LLM capabilities out of the box, with built-in application evaluation and cost monitoring. Build your industry AI Agent today.
This article is part of the Enterprise AI Agent series. Related reading:
Start building today
If you need more support, please contact us