 Home
Home Products
Products Resources
Resources Solutions
Solutions Pricing
Pricing Company
Company Find Us
Find UsEnterprise RAG Guide: Retrieval to Production
Deep dive into every layer of production-grade RAG: document parsing, chunking, hybrid retrieval, and answer quality.

Summary
Large language models carry impressive general knowledge, but they know nothing about your internal policies, product specs, or compliance documents. RAG (Retrieval-Augmented Generation) bridges that gap by connecting general-purpose AI with your proprietary knowledge base. This guide walks through every layer of a production-grade RAG system — vector database selection, document parsing, chunking strategies, retrieval optimization, and answer quality control — drawing on real deployment experience with Tencent Cloud ADP.
Key Takeaways:
- RAG's core mission: making LLM responses factually grounded, not just fluent
- Document parsing and chunking quality determine 80% of your RAG system's accuracy ceiling
- Pure vector search isn't enough — hybrid retrieval (vector + keyword) is the production standard
- Enterprise RAG is as much a knowledge governance practice as it is a technical architecture
- Tencent Cloud ADP provides 28+ document format parsing and multiple retrieval strategies out of the box
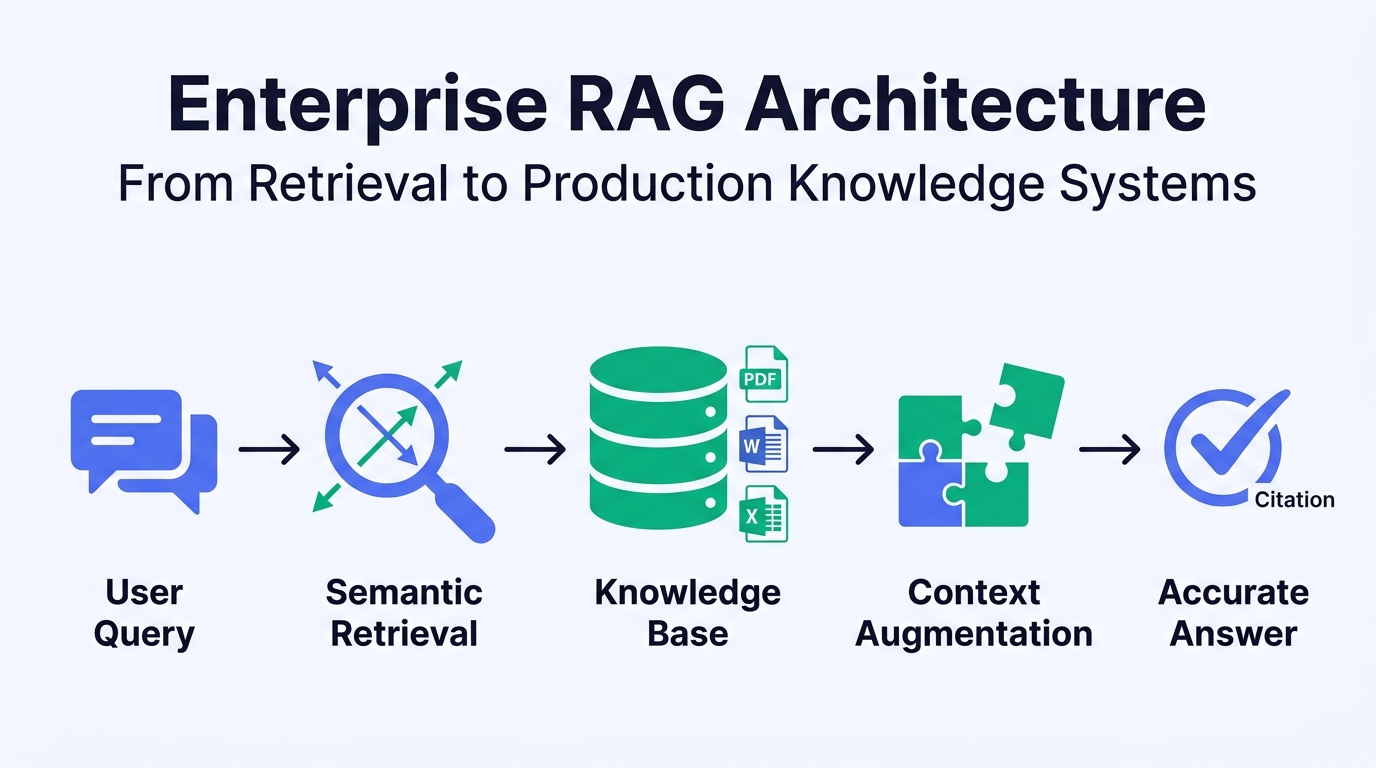
What Is RAG, and Why Do Enterprises Need It?
The LLM "Knowledge Blind Spot"
A major hotel group ran into this problem when deploying an AI concierge: the model could chat fluently about travel tips, but couldn't answer "What's the cancellation policy for executive suites?" — because that information never appeared in its training data.
This is the core problem RAG solves: giving LLMs access to knowledge they were never trained on.
RAG (Retrieval-Augmented Generation) works in four intuitive steps:
- User asks a question → the system converts it into a semantic vector
- Retrieve → find the most relevant document chunks from your knowledge base
- Augment → inject retrieved content as context into the prompt
- Generate → the LLM produces an accurate answer grounded in real documents
RAG vs. Fine-Tuning: Complementary, Not Competing
Many teams debate whether to use RAG or fine-tuning. In practice, they solve different problems.
| Dimension | RAG | Fine-Tuning |
|---|---|---|
| Core function | Inject external knowledge for fact-based Q&A | Adapt model behavior and domain style |
| Knowledge updates | Instant — update documents, done | Requires retraining (days to weeks) |
| Cost | Low incremental cost (retrieval + storage) | High (GPU compute for training) |
| Hallucination control | Answers traceable to source documents | Still prone to hallucination |
| Best for | Knowledge-intensive Q&A, document search, support | Style adaptation, task-specific optimization |
| Data privacy | Data stays in your knowledge base, never enters the model | Data participates in the training process |
Field insight: Among enterprise customers on Tencent Cloud ADP, over 90% of knowledge Q&A scenarios are fully served by RAG alone. Only a small fraction requiring deep domain adaptation need additional fine-tuning.
What RAG Can — and Cannot — Do
RAG is not a silver bullet. Understanding its boundaries leads to better architecture decisions.
RAG excels at:
- Internal knowledge base Q&A (policies, processes, manuals)
- Product knowledge queries in customer service
- Legal and compliance document retrieval
- Technical documentation and API reference lookup
- Research report analysis and industry intelligence extraction
RAG is not ideal for:
- Multi-step reasoning and complex calculations
- Highly creative content generation
- Extremely small knowledge sets (under a few dozen entries) — just put them in the prompt
- Real-time data stream processing (e.g., live stock prices)
How RAG Works: Architecture Deep Dive
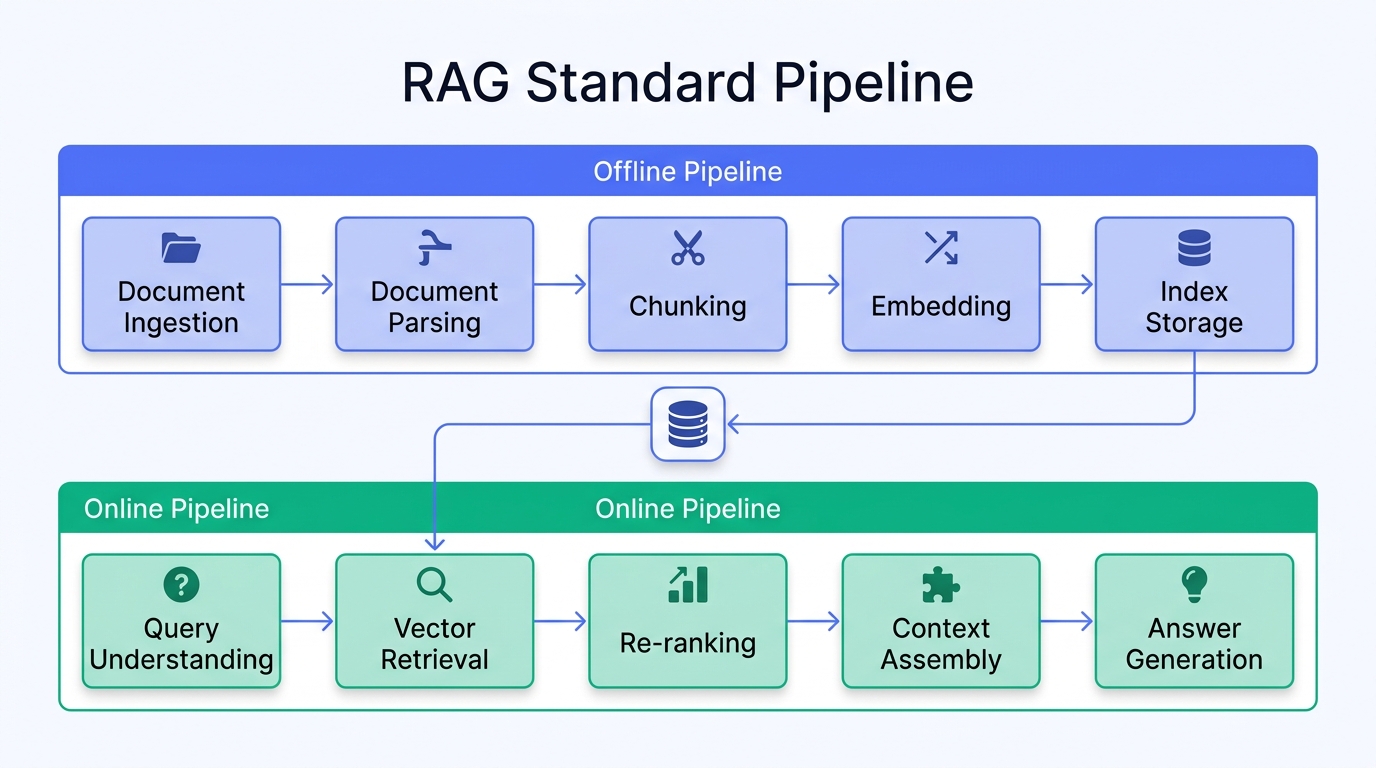
The Standard RAG Pipeline
A production-grade RAG system runs two parallel tracks:
Offline Pipeline (Data Preparation):
| Step | What happens | Key metric |
|---|---|---|
| Document ingestion | Collect raw documents from files, databases, APIs | Format coverage |
| Document parsing | Convert PDF, Word, PPT to structured text | Parsing accuracy |
| Chunking | Split long documents into semantically complete segments | Chunk quality |
| Embedding | Convert text chunks into vectors via embedding models | Semantic fidelity |
| Indexing | Write vectors to vector database and build indices | Retrieval latency |
Online Pipeline (Query Processing):
| Step | What happens | Key metric |
|---|---|---|
| Query understanding | Parse user intent, rewrite query if needed | Intent accuracy |
| Vector retrieval | Find most similar document chunks | Recall rate |
| Re-ranking | Re-score results for relevance | Precision |
| Context assembly | Compose structured prompt from relevant chunks | Context utilization |
| Answer generation | LLM generates response based on context | Answer accuracy |
From "Working" to "Working Well": Advanced RAG Patterns
Basic RAG performs acceptably in PoC, but production environments expose its limitations. Here are three advanced patterns:
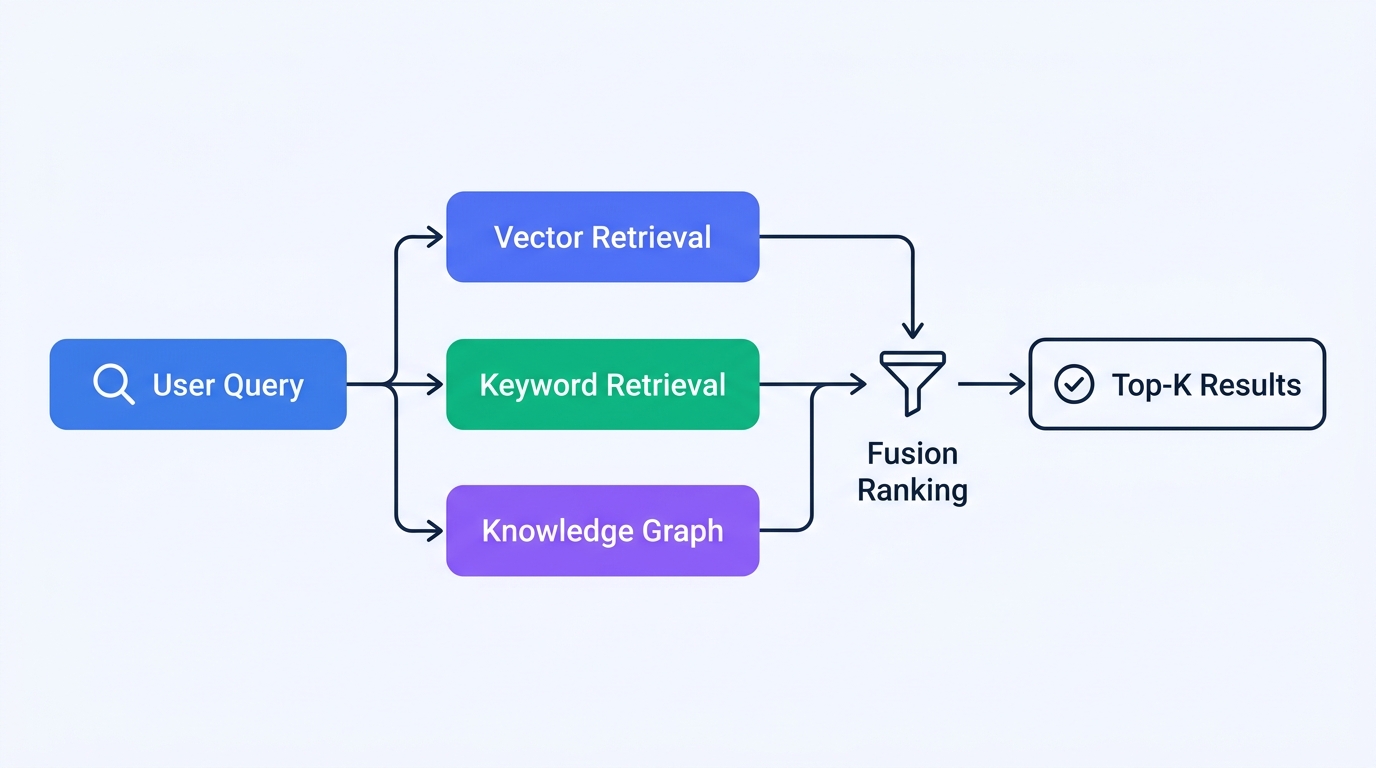
Pattern 1: Multi-Route Retrieval Fusion
Single-mode vector search can't cover every query type. When a user searches for "warranty period in years," keyword matching may outperform semantic search.
Pattern 2: Query Rewriting and Decomposition
User questions are often imprecise. Query rewriting significantly improves retrieval quality:
| Strategy | Original query | Rewritten | Effect |
|---|---|---|---|
| Intent clarification | "how do I handle insurance" | "How to file a vehicle insurance claim" | Removes ambiguity |
| Question decomposition | "Is A or B better?" | "Features of A" + "Features of B" | Splits complex queries |
| Hypothetical document | "return process" | Generate an "ideal answer" to use for retrieval | Improves semantic matching |
Pattern 3: Adaptive Retrieval (Agentic RAG)
The most advanced RAG architectures use an Agent to dynamically choose retrieval strategies:
- Simple factual query → direct vector retrieval
- Multi-condition query → structured query + vector retrieval
- Cross-document analysis → iterative multi-round retrieval + information aggregation
- Answerable from existing context → skip retrieval, generate directly
Document Parsing: The Foundation of RAG
Why Parsing Quality Matters More Than You Think
Here's a counterintuitive finding from numerous enterprise RAG projects: document parsing quality has a far greater impact on final performance than model selection or retrieval algorithm optimization.
A PDF financial report with nested tables, charts, and complex layouts — if the parsing stage loses the table structure, no amount of vector model improvement will fix the downstream results.
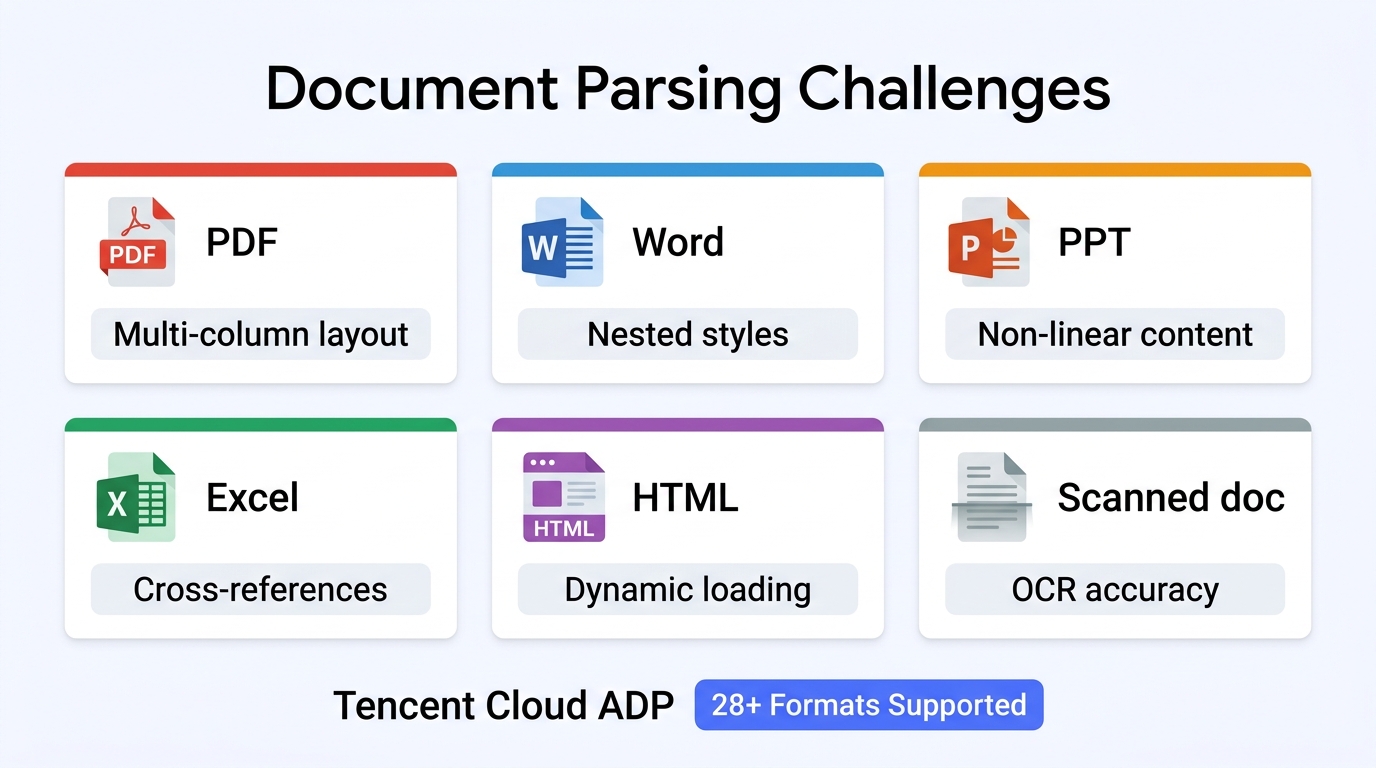
Common Document Formats and Parsing Challenges
| Format | Core challenge | Common issues |
|---|---|---|
| Unstructured layout, scanned documents | Multi-column layout errors, table structure loss, text in images unextracted | |
| Word/DOCX | Nested styles, comments, tracked changes | Tables breaking across pages, text box content missed |
| PPT | Non-linear content, mixed media | Slide order vs. logical flow mismatch, SmartArt unparseable |
| Excel | Cross-sheet references, formulas | Formula results lost, merged cell parsing errors |
| HTML | Dynamic loading, ad noise | Effective content identification, nav/footer interference |
| Scanned docs | OCR accuracy, layout analysis | Low handwriting recognition, complex layout restoration |
Document Parsing on Tencent Cloud ADP
Tencent Cloud ADP includes an enterprise-grade document parsing engine supporting 28+ document formats:
| Capability | Specification | Business value |
|---|---|---|
| Format support | PDF, Word, Excel, PPT, HTML, Markdown, TXT, and 28+ more | Upload directly, no preprocessing needed |
| Max file size | 200MB | Large technical manuals and compliance docs — no problem |
| Table parsing | Auto-detects and preserves table structure | Accurate retrieval from table-heavy financial and spec documents |
| OCR | Integrated Tencent Cloud OCR for scans and images | Digitize legacy paper documents |
| Multi-language | Chinese, English, Japanese, and more | Cross-border enterprise multilingual knowledge bases |
Reference data: A major hotel group achieved 95%+ knowledge base accuracy, sub-5-second first-token response, and reduced FAQ maintenance from 1,000+ entries to 100+ after deploying on Tencent Cloud ADP.
Chunking Strategies: Making Knowledge "Just Right" for Retrieval
Why Chunking Matters
Chunking is the critical step between document parsing and vectorization. Chunk quality directly determines:
- Whether retrieval finds "just enough" information
- Whether context windows are wasted
- Whether answers are complete or truncated
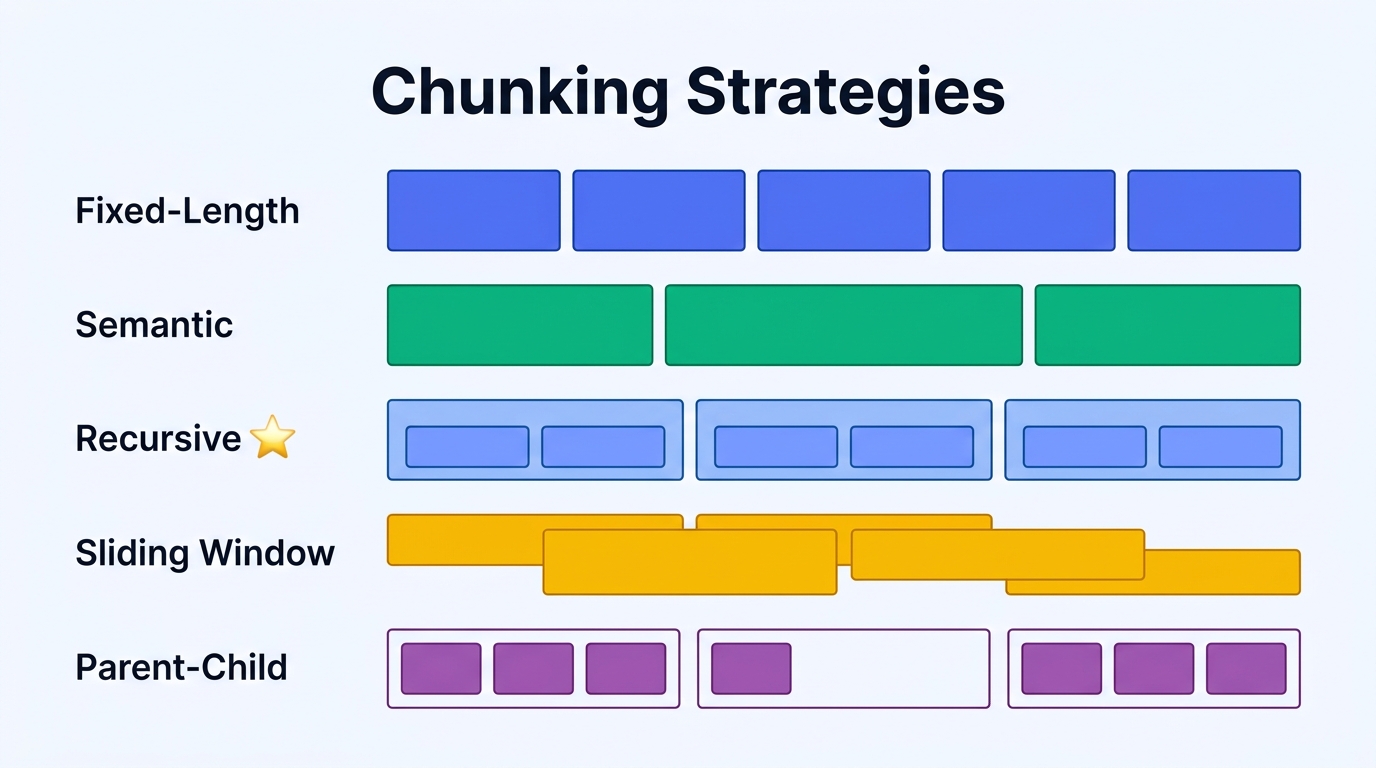
Comparing Mainstream Chunking Strategies
| Strategy | How it works | Strength | Limitation | Best for |
|---|---|---|---|---|
| Fixed-length | Split by character or token count | Simple, predictable | May break mid-sentence | Uniform plain text |
| Semantic | Split at paragraph/section boundaries | Preserves semantic units | Uneven chunk sizes | Well-structured documents |
| Recursive | Split at coarse grain, then refine | Balances semantics and size | Requires multi-level separator tuning | General-purpose (recommended default) |
| Sliding window | Fixed window with overlap | Prevents information loss | Storage redundancy | Narrative long-form content |
| Parent-child | Small chunks for retrieval, large for context | Precise retrieval + full context | Higher index complexity | Technical docs, legal texts |
Practical Chunking Recommendations
Recommended configuration (suitable for most enterprise scenarios):
| Parameter | Recommended value | Rationale |
|---|---|---|
| Chunk size | 300–500 tokens | Balances precision and context completeness |
| Overlap | 50–100 tokens | Prevents key information from being cut off |
| Separator priority | Heading > Paragraph > Sentence | Split at natural boundaries first |
| Metadata retention | Document title + section title + page number | Improves post-retrieval navigation |
Avoiding pitfalls: Don't chase the "optimal chunk size" — it varies by document type and business scenario. A better approach: prepare a representative query set, test different parameters, and pick the configuration that performs best on your evaluation set.
Vector Databases: Selection and Performance
The Role of Vector Databases in RAG
The vector database is the "memory core" of a RAG system. It stores vector representations of document chunks and enables fast similarity search at query time.
Comparing Popular Vector Databases
| Solution | Type | Strengths | Limitations | Best for |
|---|---|---|---|---|
| Milvus | Dedicated vector DB | Distributed architecture, billion-scale vectors | Higher operational complexity | Large-scale production |
| Pinecone | Fully managed service | Zero ops, ready to use | Data sovereignty concerns | North American rapid prototyping |
| Weaviate | Vector + traditional search | Built-in hybrid search | Community edition limits | Scenarios needing hybrid search |
| pgvector | PostgreSQL extension | Reuses existing DB infrastructure | Limited at large scale | Small-scale or existing PG teams |
| Qdrant | High-performance vector DB | Rust implementation, excellent performance | Ecosystem less mature than Milvus | Performance-sensitive scenarios |
| Platform-integrated | Tencent Cloud ADP | All-in-one, no separate deployment | Less customization room | Enterprise rapid deployment |
Hybrid Retrieval: The Production Standard
In real-world scenarios, pure vector retrieval alone often falls short:
- When users search for specific model numbers like "XR-7200," keyword matching outperforms semantic search
- When users ask about "warranty policy," semantic search finds content phrased differently but with the same meaning
Typical hybrid retrieval configuration:
| Retrieval mode | Weight | Best for |
|---|---|---|
| Vector search (semantic) | 0.6 | Generalized semantic queries |
| Keyword search (BM25) | 0.3 | Exact terms and ID matching |
| Metadata filtering | 0.1 | Filtering by time, department, document type |
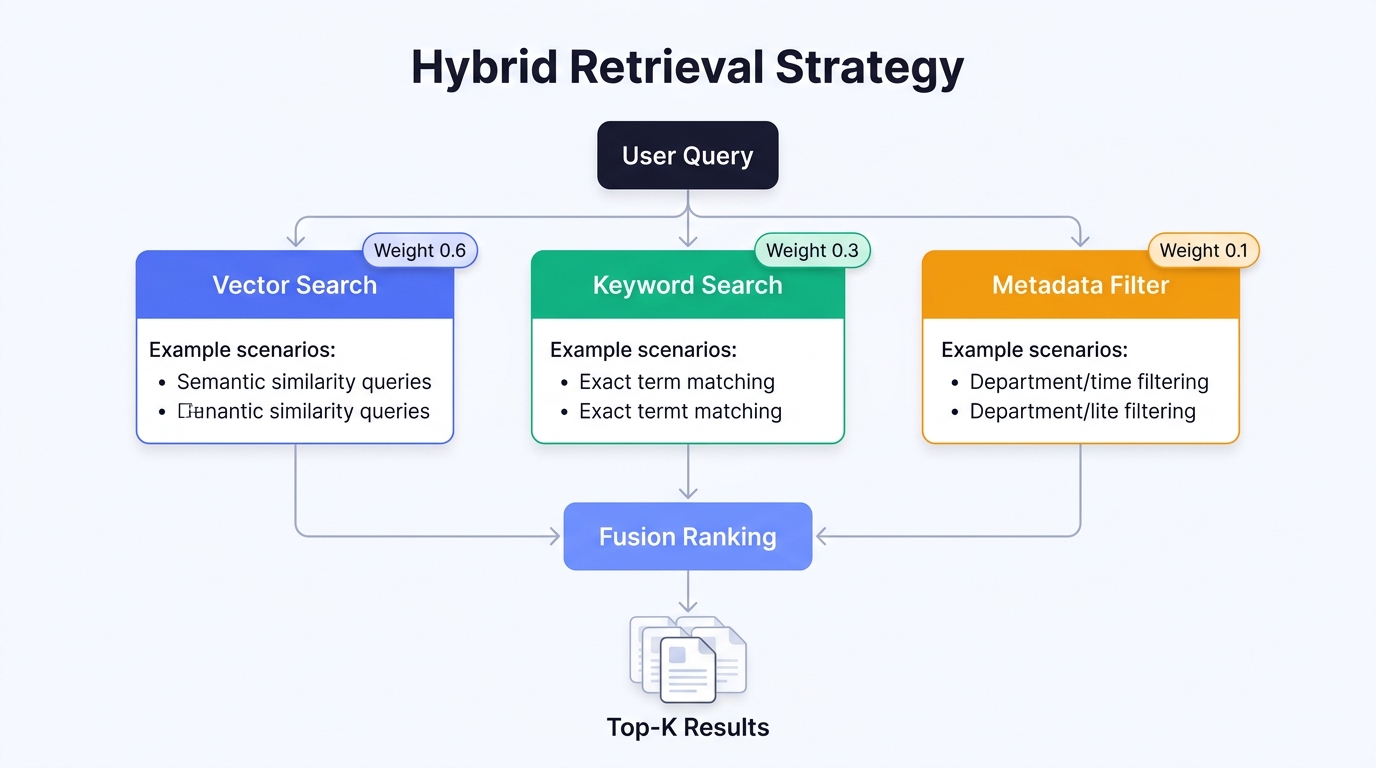
Best practice: Tencent Cloud ADP's knowledge base module includes built-in hybrid retrieval that automatically fuses vector and keyword search — no manual weight tuning needed. For most enterprise scenarios, the default configuration delivers strong results out of the box.
From PoC to Production: The Complete Enterprise RAG Roadmap
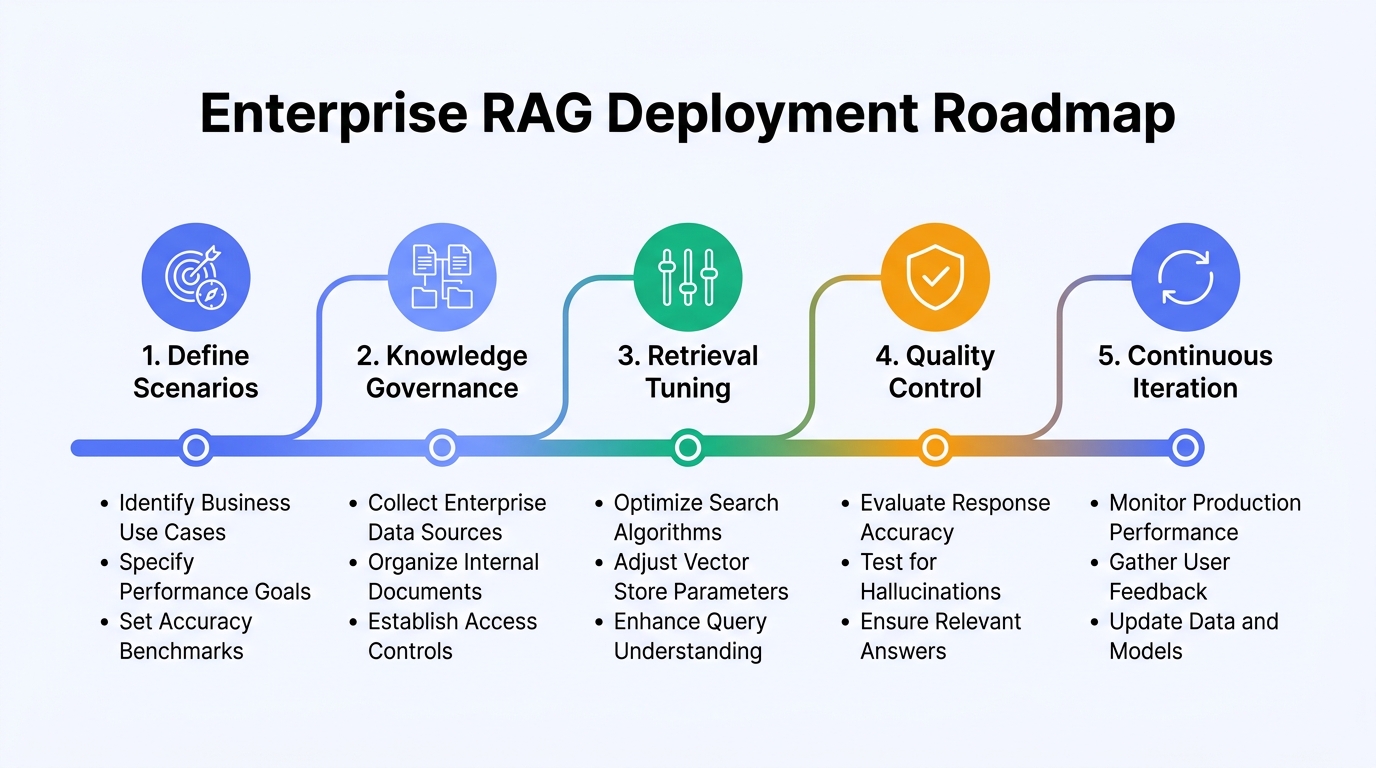
Step 1: Define Business Scenarios and Knowledge Scope
Before building anything, answer three questions:
| Question | What to define | Deliverable |
|---|---|---|
| Who uses it? | Target user personas (support agents, employees, customers) | User role inventory |
| What do they ask? | Top 50 most frequent questions | Evaluation dataset |
| Where does knowledge live? | Source types, formats, update frequency | Knowledge source inventory |
Step 2: Knowledge Base Construction and Quality Governance
A knowledge base isn't "dump documents and go." Here's a proven governance workflow:
- Document cleanup: Remove outdated versions, duplicates, low-quality content
- Structure standardization: Unify document formats, heading levels, terminology
- Tagging system: Label by business domain, document type, update timestamp
- Version management: Automate document updates → knowledge base sync
- Quality validation: Verify parsing and retrieval with your evaluation dataset
Step 3: Retrieval Strategy Optimization
| Optimization area | Techniques | Expected impact |
|---|---|---|
| Improve recall | Hybrid retrieval, query expansion, synonym mapping | Fewer "no answer found" cases |
| Improve precision | Re-ranking models, metadata filtering | Less noise in results |
| Speed | Index warm-up, cache hot queries | First-token latency < 3s |
| Multi-turn conversation | Context stitching, dialogue history management | Continuity across follow-up questions |
Step 4: Answer Quality Control
Retrieval is only step one. The generation phase needs rigorous controls:
- Citation tagging: Every answer cites its source document — users can trace back with one click
- Confidence scoring: Quantify answer reliability; low-confidence answers trigger human review
- Fallback strategy: When no relevant content is found, don't fabricate — route to human support
- Answer consistency: The same question should produce consistent answers across sessions
Step 5: Continuous Monitoring and Iteration
Production RAG requires ongoing operations, not one-time deployment:
| Monitoring dimension | Core metric | Target |
|---|---|---|
| Retrieval quality | Recall, precision | ≥ 85% |
| Answer accuracy | Human-reviewed accuracy | ≥ 90% |
| Response performance | First-token latency, end-to-end latency | P95 < 5s |
| User satisfaction | Thumbs-up rate, repeat question rate | Satisfaction > 80% |
| Knowledge coverage | "Unable to answer" percentage | < 10% |
Real-World Results: RAG in Enterprise Deployments
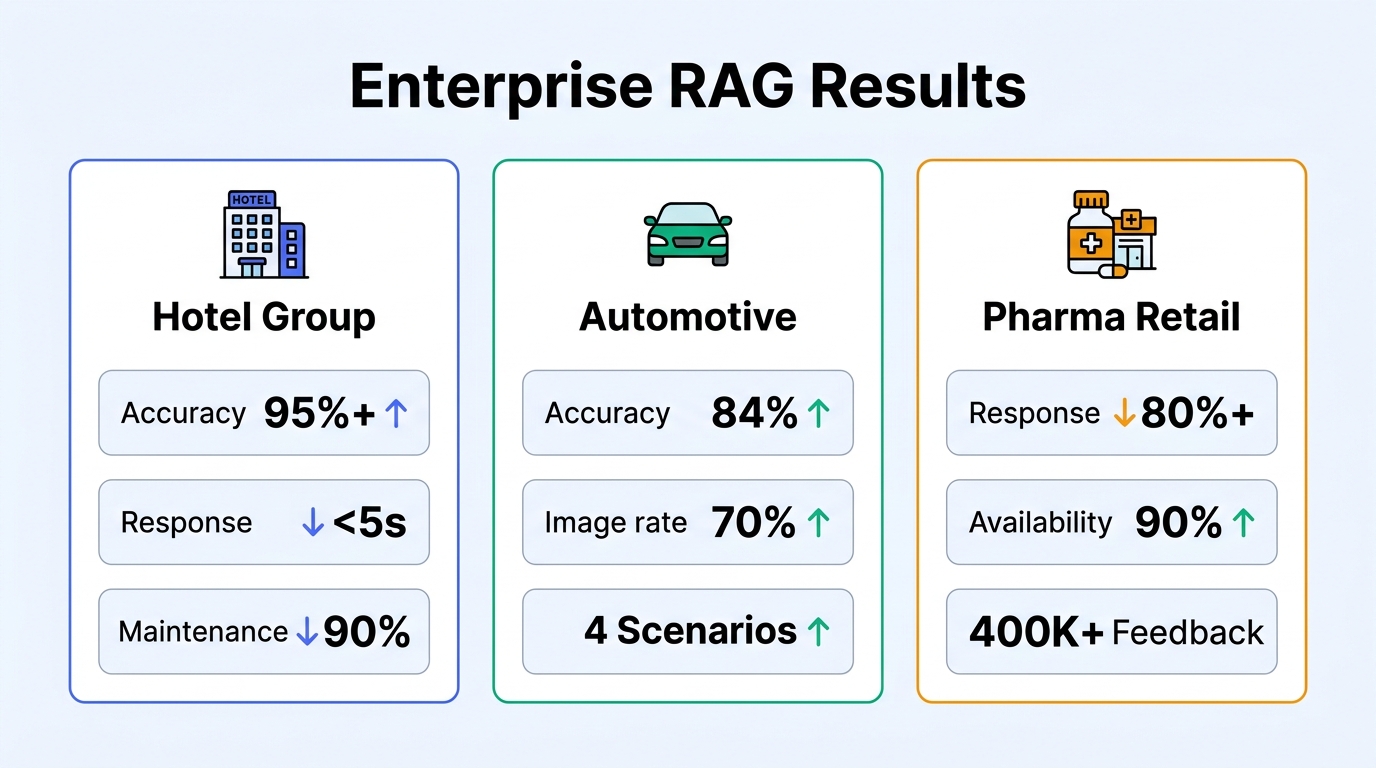
Case 1: Major Hotel Group — Smart Concierge Knowledge Base
A major hotel group deployed a RAG-based intelligent concierge system using Tencent Cloud ADP:
| Metric | Before | After |
|---|---|---|
| Knowledge base accuracy | ~60% (keyword-based) | 95%+ (RAG-based) |
| First-token response | 8–12 seconds | < 5 seconds |
| FAQ maintenance | 1,000+ manually maintained entries | 100+ core rules |
| Human escalation rate | ~40% | Significantly reduced |
| Error rate | Frequent irrelevant answers | Reduced by 60% |
| Daily agent time saved | — | 0.5–1 hour |
Case 2: Leading Automotive Manufacturer — Full-Scenario Customer Service
A leading automotive manufacturer deployed a Multi-Agent + RAG customer service system:
| Metric | Result |
|---|---|
| Accuracy | 84% |
| Image response rate | 70% (mixed text-image answers) |
| Scenario coverage | Pre-sales, vehicle use, after-sales, emergency rescue |
Case 3: Top Pharmaceutical Retailer — Drug Information Q&A
A top pharmaceutical retailer built a professional drug information Q&A system with RAG:
| Metric | Result |
|---|---|
| Response time improvement | Reduced by 80%+ |
| Drug Q&A availability | 90% |
| Feedback analysis | 400,000+ user feedback entries auto-analyzed |
Frequently Asked Questions
Q1: What's the relationship between RAG and vector databases?
RAG is an architecture pattern; a vector database is one component within it. The vector database stores document vector representations and provides efficient similarity search, but a complete RAG system also includes document parsing, chunking, query rewriting, re-ranking, and answer generation.
Q2: How large does a knowledge base need to be before RAG makes sense?
There's no strict threshold. If your entire knowledge fits within the LLM's context window (current models support 128K tokens or more) and doesn't need frequent updates, putting content directly in the prompt may be simpler. But once you have more than a few dozen pages, need regular updates, or require answer traceability, RAG becomes the better choice.
Q3: What accuracy can a RAG system typically achieve?
It depends on knowledge base quality, document parsing effectiveness, and retrieval strategy. In real customer deployments on Tencent Cloud ADP, optimized RAG systems typically achieve 85%–95% accuracy. Document parsing quality and chunking strategy have the greatest impact on accuracy.
Q4: How does a RAG system handle knowledge updates?
One of RAG's key advantages is instant knowledge updates. After updating a document, the system re-parses and re-vectorizes it — new knowledge becomes immediately searchable. Compared to fine-tuning, which requires retraining, RAG's knowledge update cost is effectively zero.
Q5: Should we build RAG from scratch or use a platform?
It depends on your team size and technical capabilities. Building RAG in-house means handling document parsing, vector database operations, retrieval algorithm optimization, and significant engineering work — suitable for companies with dedicated AI infrastructure teams. For most enterprises, an all-in-one platform like Tencent Cloud ADP can reduce time-to-production from months to weeks while providing continuous platform upgrades.
Q6: Can RAG support multilingual scenarios?
Yes. RAG's multilingual support depends primarily on two factors: whether the embedding model supports the target language, and whether document parsing can handle target-language documents. Tencent Cloud ADP supports document parsing and semantic retrieval in Chinese, English, Japanese, and other major languages.
Q7: How do you evaluate a RAG system's quality?
Evaluate across four dimensions: retrieval recall (can it find relevant documents?), answer accuracy (are generated answers correct?), response latency (how long do users wait?), and knowledge coverage (what percentage gets "unable to answer"?). Build an evaluation dataset of 50–100 representative questions and run periodic benchmarks — that's the most practical approach.
Ready to build your enterprise RAG system?
→ Start Free Trial with Tencent Cloud ADP
*This article is part of the Enterprise AI Agent series.Related reading:
Start building today
If you need more support, please contact us