酒店智能服务助手实战复盘
从单工作流到标准模式:一个头部连锁酒店的 AI Agent 落地复盘

摘要
一家头部连锁酒店集团在自有 App 内上线了"24 小时数字管家"——酒店智能服务助手。项目的硬指标是:回复准确率 ≥95%,首 token 耗时 ≤5s。
这篇文章复盘整个落地过程,包括:
- 为什么从"单工作流模式"切换到"标准模式"
- 多意图 query、语种切换、拒答防幻觉的工程解法
- 哪些场景走 RAG,哪些场景必须走结构化查询
本文不涉及任何公司主体、客户信息或敏感规模数据,只讲流程、方法论与实操路径。
前提条件
开始之前,确保你有:
- [ ] Agent 构建平台的访问权限(本文以腾讯云 ADP 为参考)
- [ ] 酒店业务系统对接权限(工单系统、PMS、IoT 客控等)
- [ ] 业务场景清单与意图定义
- [ ] 定义好的成功指标(准确率、时延、转人工率)
时间估算: 从启动到首版上线约 4-6 周,持续调优贯穿运营全周期
第 1 步:定义范围和成功指标
为什么重要: 酒店智能助手最容易失败的原因不是模型能力,而是范围失控——把"智能助手"当成"万能客服"。
1.1 范围定义框架
动手写提示词之前,先把这些问题想清楚:
| 问题 | 差的回答 | 好的回答 |
|---|---|---|
| Agent 将处理什么查询? | "住客问题" | "送物、酒店信息、设施查询、Wi-Fi/开票、周边推荐、房间客控" |
| 准确率要求是什么? | "尽可能准确" | "回复准确率 ≥95%,边缘情况转人工" |
| 延迟要求是什么? | "快" | "首 token ≤5s" |
| 需要集成什么系统? | "酒店系统" | "工单系统(写)、PMS(读)、IoT 客控(写)、地图/天气 API(读)" |
| 什么不在范围内? | (空白) | "支付纠纷、隐私安全、强烈投诉、法律/医疗咨询" |
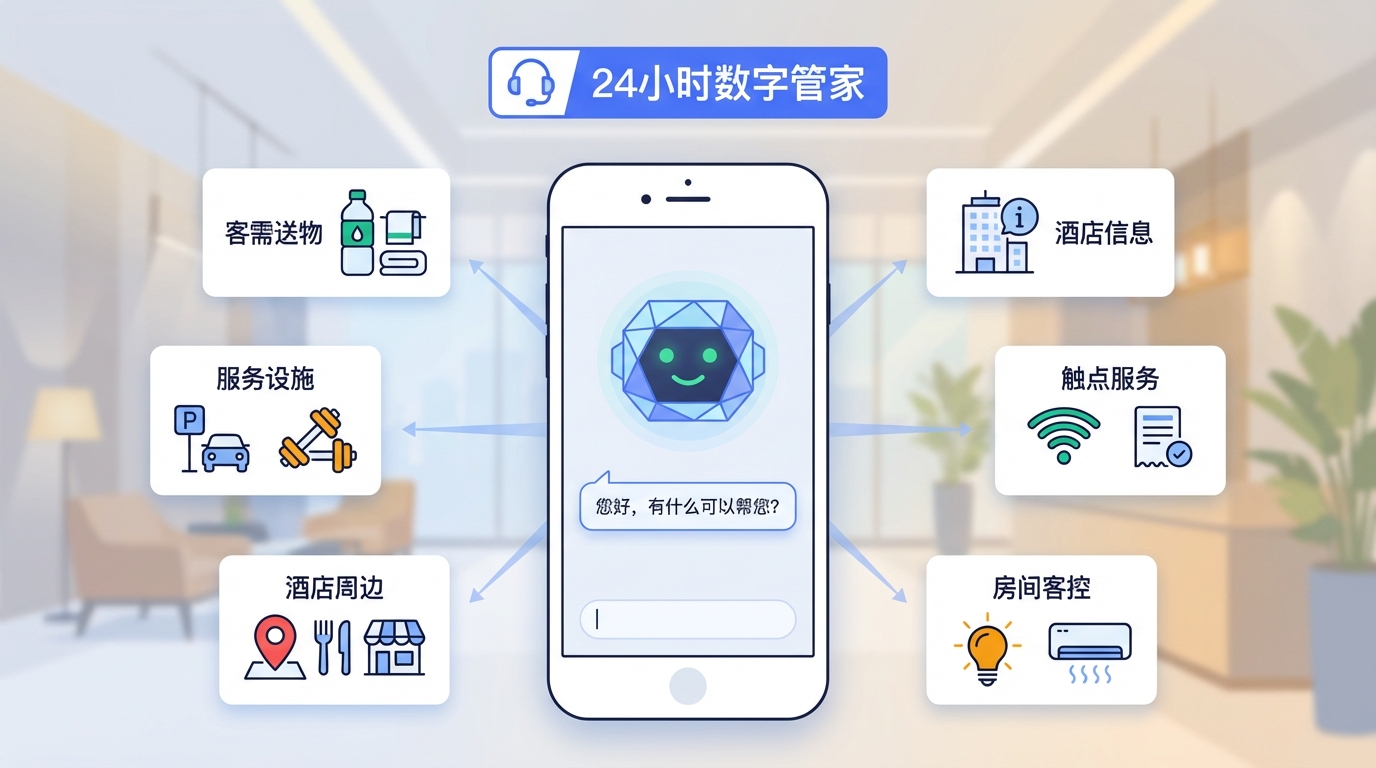
1.2 In Scope(范围内)
本助手优先覆盖以下"标准化、高频、可验收"的能力:
| 场景 | 描述 | 关键动作 |
|---|---|---|
| 客需送物 | 送水、送六小件等 | 意图识别 → 参数提取 → 生成工单 → 配送 |
| 酒店信息 | 电话、地址、入住时间、政策 | 结构化数据查询(不走 RAG) |
| 服务设施 | 停车场、餐厅、健身房、会议室 | 数据库查询 |
| 触点服务 | Wi-Fi、开票、含早、洗衣 | 查询/跳转第三方 |
| 酒店周边 | 天气、交通、景点、美食 | 地图/天气能力调用 |
| 房间客控 | 灯/窗帘/空调/电视控制 | 参数提取 → IoT 下发 |
1.3 Out of Scope(范围外)
任何涉及敏感信息、强主观判断或不可控承诺的事项,默认转人工:
- 支付纠纷、退款争议、账务异常
- 隐私/安全相关(身份核验、敏感信息变更)
- 强烈投诉/冲突升级
- 法律/医疗等高风险咨询
- 任何需要"写入核心系统"的动作(默认只读;写操作必须二次确认 + 审计留痕)
1.4 成功指标
上线前就要定好这些指标——别等上线后再想:
| 指标 | 目标 | 说明 |
|---|---|---|
| 回复准确率 | ≥95% | 定义抽样口径与"正确"的判定标准 |
| 首 token 时延 | ≤5s | 重点影响体感"是否秒回" |
| 转人工率 | 显著降低 | 区分"用户主动要人" vs "系统触发升级" |
| 满意度 | 提升 | 建议按渠道、酒店类型、时段分层看 |
第 2 步:理解业务痛点
为什么重要: 不理解痛点,就无法设计正确的解法。
酒店客户服务有一个非常典型的矛盾:
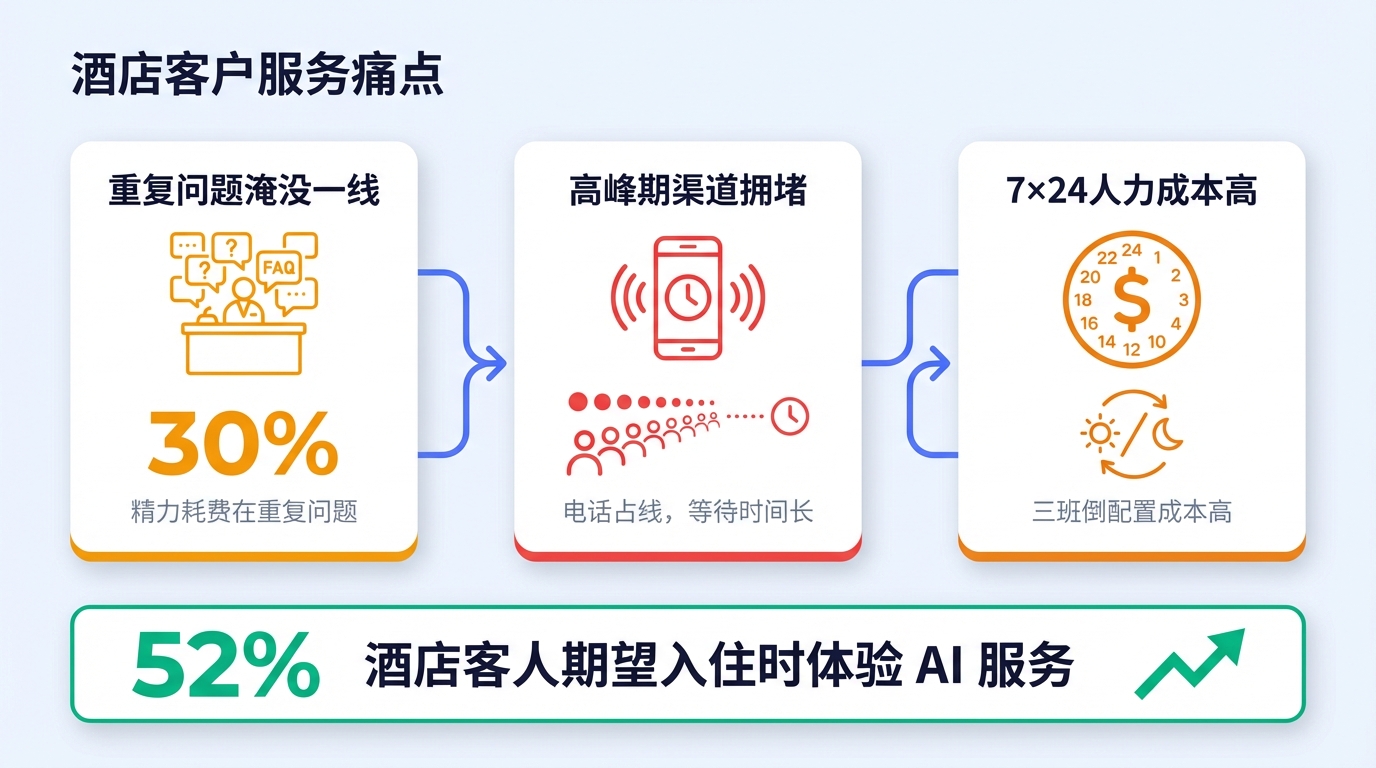
| 痛点 | 具体表现 |
|---|---|
| 一线被重复问题淹没 | 前台员工超过 30% 的精力耗费在重复性问题上("泳池开放吗?""牙刷送一下") |
| 高峰期渠道拥堵 | 电话占线,住客等待时间长,产生焦虑与不满 |
| 7×24 人力成本高 | 三班倒配置成本高,夜间咨询量少导致利用率低 |
行业数据显示:52% 的酒店客人期望入住时体验 AI 服务。这不是"锦上添花",而是"不做就落后"。
第 3 步:选择应用模式
为什么重要: 模式选错,后面全错。
3.1 三种模式对比
| 模式 | 适用场景 | 本项目适用性 |
|---|---|---|
| 单工作流模式 | 意图少(<20)、流程简单 | ✅ 初期适用 |
| 标准模式 | 意图多、需要多个工作流协作 | ✅ 中后期切换 |
| MultiAgent 模式 | 复杂多角色协作 | ❌ 本场景不需要 |
3.2 本项目的模式演进
项目初期:单工作流模式
- 无文档与 FAQ,以工作流为主
- 意图数量约 10 个,范围收敛
- 场景分两类: 1. 识别意图 → 调用插件查询 → 大模型总结回复 2. 识别意图 → 参数提取 → 调用插件下单
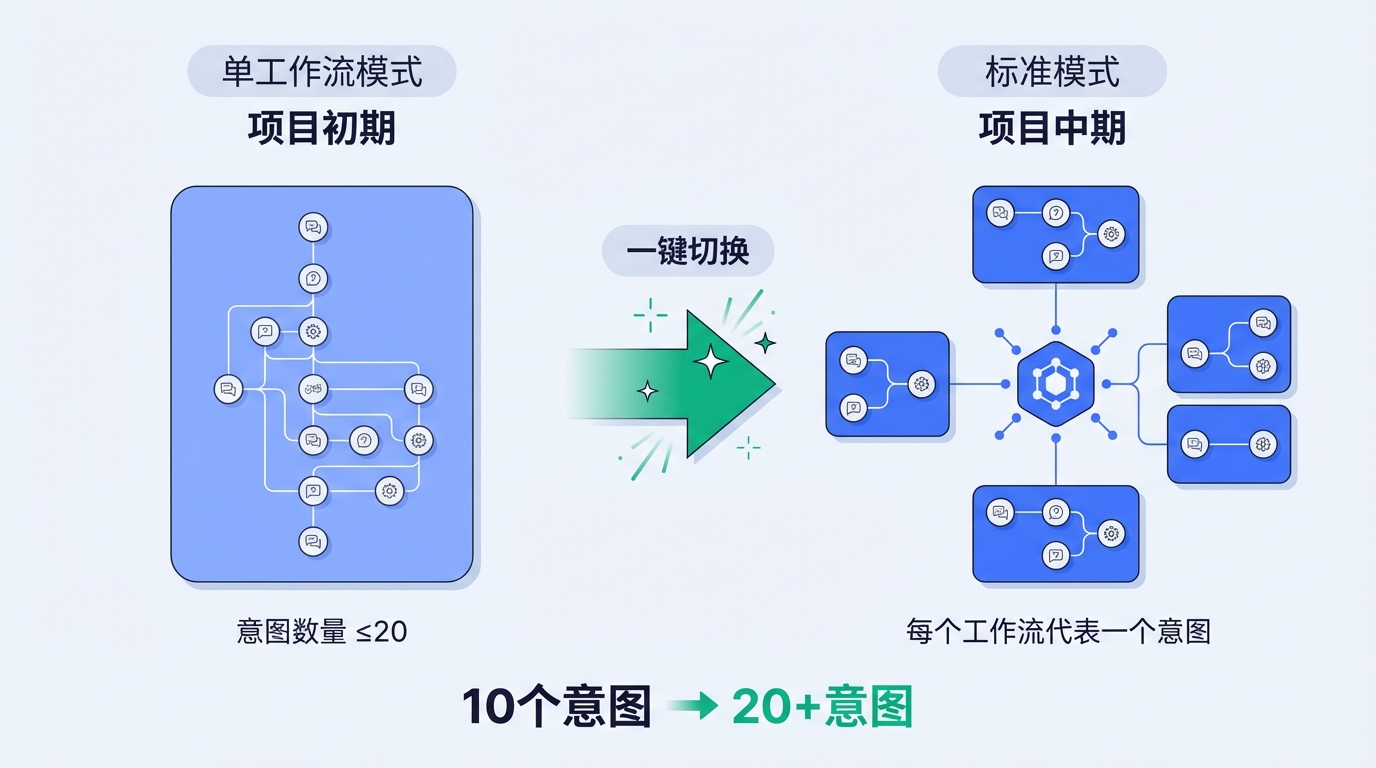
项目中期:切换到标准模式
- 需求变更,意图数量增加
- 意图识别节点有 20 个意图上限,单工作流无法承载
- 方案:切换到标准模式,每个工作流代表一个意图
- 平台能力:支持 一键从单工作流切换为标准模式
第 4 步:设计系统架构
为什么重要: 架构决定了哪些问题能解决,哪些问题会变成坑。
4.1 整体架构
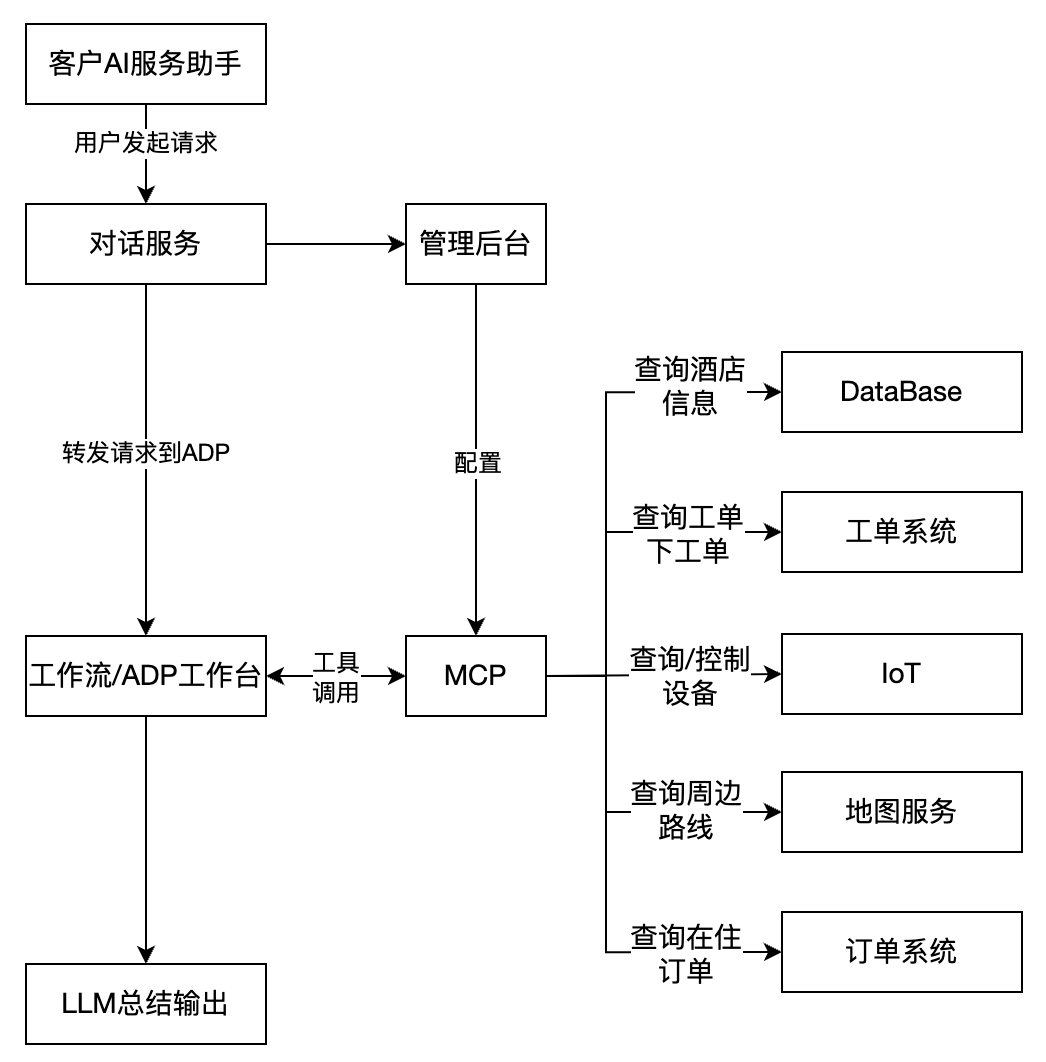
4.2 "走不走 RAG"的判定
这是本项目最关键的工程决策之一:
| 场景类型 | 典型问题 | 推荐路径 | 原因 |
|---|---|---|---|
| 结构化事实 | 入住时间、是否可带宠物 | 工具查询(DB/API) | 避免"说得像但不准确" |
| 动作型请求 | 送水、开空调 | 工作流 + 参数提取 + 工具 | 需要精确参数与执行 |
| 周边信息 | 怎么去机场 | 工作流 + 地图能力 | 结果时效性要求高 |
| 政策解释 | 未成年人政策细则 | RAG + 强约束拒答 | 需要理解长文档 |
核心原则:能结构化查询的,不走 RAG。
关于 RAG 冷启动与知识库搭建的详细方法,参见 企业如何真正将 AI Agent 落地到生产环境。
4.3 对接系统清单
| 系统 | 用途 | 权限 |
|---|---|---|
| 工单系统 | 送物、维修等住中需求 | 写 |
| PMS | 订单/入住相关数据 | 读 |
| 酒店信息库 | 酒店信息、设施信息 | 读 |
| IoT 客控 | 灯/窗帘/空调等 | 写 |
| 第三方连接 | Wi-Fi、开票、洗衣 | 读/跳转 |
| 地图/天气 | 周边推荐与路线 | 读 |
权限策略:只读优先;写操作放在最小集合,加二次确认 + 审计留痕。
第 5 步:效果调优实战经验
为什么重要: 这些问题不是"可能遇到",而是"一定会遇到"。以下是项目中沉淀的调优经验,很多是踩过坑后才总结出来的。
5.1 单条 query 包含多个意图,怎么全答?
场景还原
住客发来一条消息:"帮我修一下马桶,另外停车场怎么收费,还有我想改成大床房"。
这条 query 包含三个独立意图:维修请求、设施咨询、房型变更。但在标准的意图识别流程中,系统只会命中其中一个工作流(通常是第一个或置信度最高的),其余意图被忽略或拒答。
为什么会这样?
大多数 Agent 框架的意图识别是"单选"逻辑:一条 query 对应一个意图,进入一个工作流。这在单意图场景下没问题,但酒店住客的真实表达往往是"顺嘴一起问"。
工程解法
我们新增了一个"多意图入口工作流",专门处理这类情况:
- 识别多意图:在工作流描述中明确写入多意图示例(如"维修 + 咨询 + 改房"),并强调"当识别到多条意图时优先进入本工作流"
- 拆分意图:用代码节点将 query 拆成意图数组,例如
["维修马桶", "停车场收费", "改大床房"] - 循环分发:遍历数组,逐条调用主流程,主流程再基于自定义意图分发到对应子工作流
- 合并输出:收集各子工作流的回复,拼接成一条完整回答
关键细节
- 意图模型建议选用更稳定的版本(项目中切换到
youtu-intent-pro后效果更好) - 多意图工作流的优先级要高于单意图工作流,否则会被"抢走"
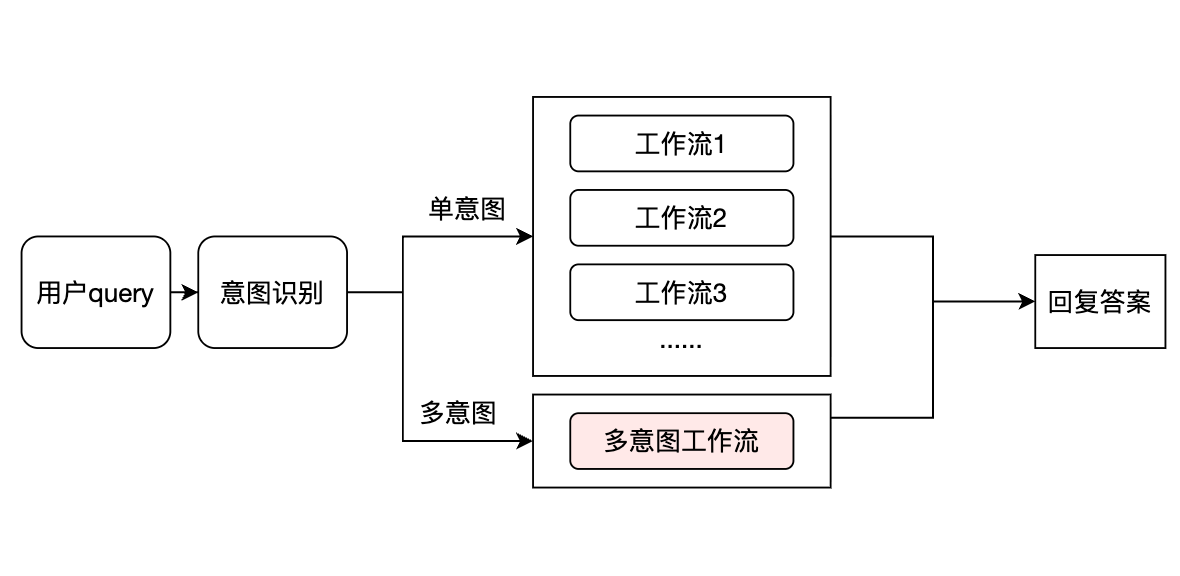
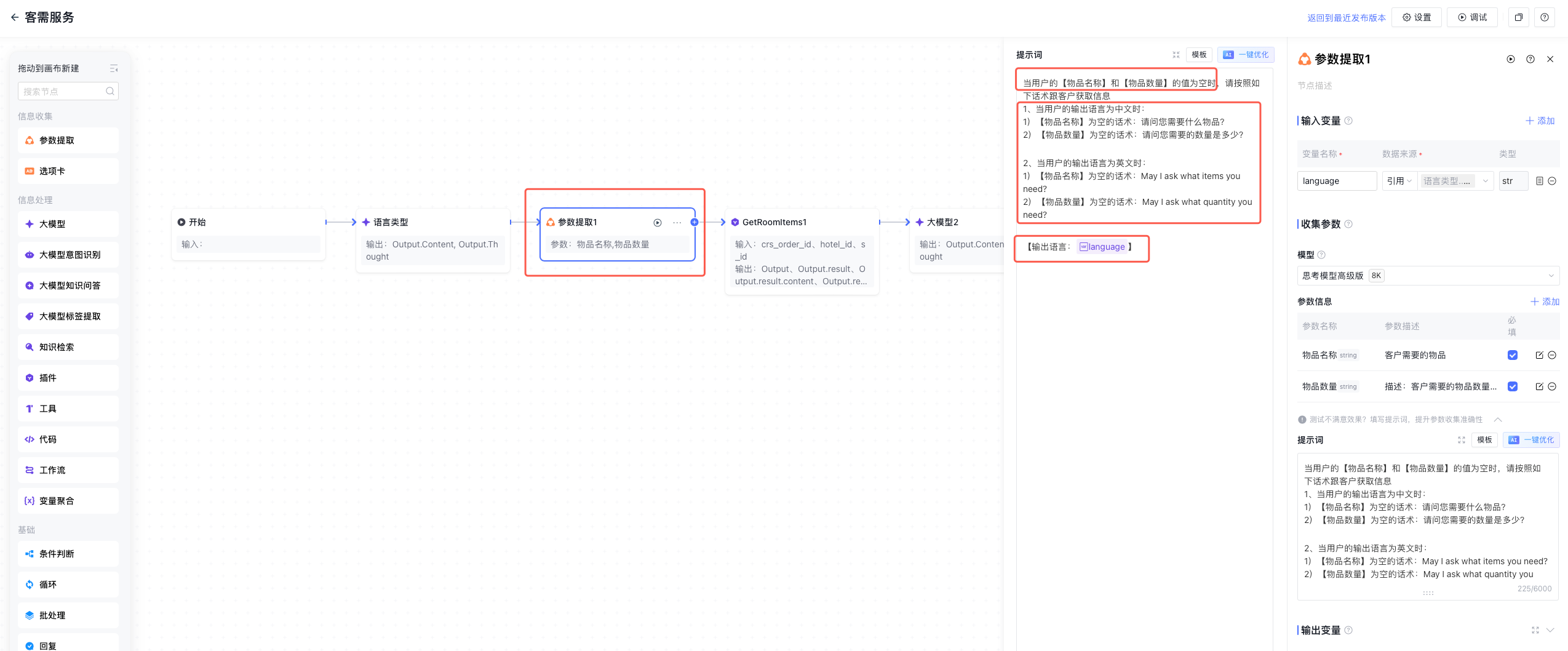
5.2 多语言场景下,如何保证"中文问中文答"?
场景还原
酒店住客来自不同国家,有人用中文问,有人用英文问。期望是:输入什么语言,就用什么语言回复。
最初的做法是在提示词里加一句"请根据用户输入的语言回复"。单轮测试没问题,但多轮对话后开始出现中英混杂,甚至回复语言和输入语言完全不一致。
为什么会这样?
提示词约束在多轮上下文中会被"稀释"。当对话历史变长、变量变多时,模型对语言约束的遵循概率下降。这不是模型"不听话",而是约束信号在长上下文中被淹没了。
工程解法
把语言判断从"软约束"变成"硬变量":
- 语言判断节点:在工作流开始处增加一个大模型节点,专门判断 query 的语言,输出变量
output_language(值为zh/en/ja等) - 全局引用:后续所有回复节点、参数提取节点都引用
output_language,在提示词中明确"用 {{output_language}} 回复" - 固定话术库:兜底回复、拒答话术、确认话术等,不要让模型临时翻译,而是提前人工翻译好,按语言变量调用对应版本 !Clipboard_Screenshot_1767182143.png !Clipboard_Screenshot_1767182177.png
关键细节
- 参数提取节点的追问话术也要做多语言配置,否则会出现"中文问 → 英文追问"的割裂体验
- 语言判断节点的 prompt 要简洁,只做一件事,避免引入额外不确定性
5.3 用户问了不存在的实体,怎么防止模型胡编?
场景还原
住客问:"你们的海景套房多少钱?"但这家酒店根本没有"海景套房"这个房型。
期望的回答是:"抱歉,我们酒店目前没有海景套房,您可以看看我们的城景大床房或豪华双床房。"
实际的回答是:"海景套房每晚 1280 元,含双早,可以看到无敌海景……"——完全是编的。
为什么会这样?
大模型的"幻觉"本质是在缺乏事实约束时,基于语言模式生成"看起来合理"的内容。当知识库或数据库查不到结果时,如果没有明确的拒答指令,模型会倾向于"补全"一个答案。
工程解法
- 明确拒答规则:在提示词中加入硬约束——"如果查询结果为空或实体不存在,必须明确告知用户,不得编造信息"
- 约束位置前置:把拒答规则放在提示词的前部或用特殊标记强调,不要埋在大段变量内容之后。经验表明,关键约束放在提示词末尾时,遵循率会下降
- 单节点调试验证:用单节点调试功能,专门测试"不存在实体"的 case,确认拒答是否稳定触发
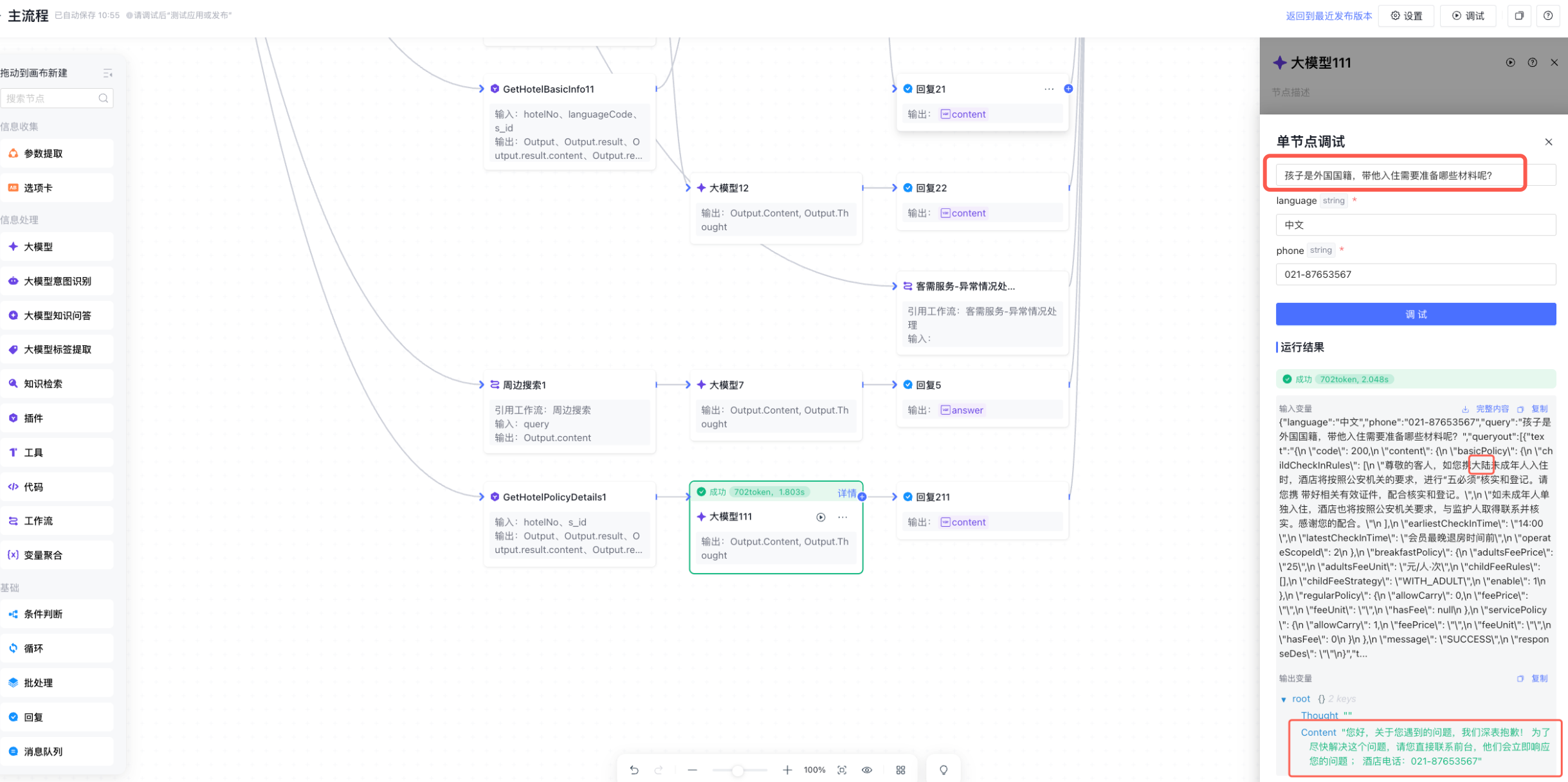
关键细节
- 如果某些政策本身有限定条件(如"仅限大陆身份证"),这些限定要写进知识文档,而不是只靠提示词约束
- 拒答后最好给出替代建议("没有 A,但有 B 和 C"),而不是干巴巴说"没有"
5.4 意图识别总是错,怎么快速干预?
场景还原
住客说"空调太冷了",期望命中"客控"意图(调高温度),但系统识别成了"投诉"意图,触发了转人工流程。
类似的 case 还有很多:用户的表达方式千奇百怪,和训练数据的分布不一致时,意图识别就容易出错。
为什么会这样?
意图识别模型是基于有限样本训练的,无法覆盖所有真实表达。尤其是口语化、省略主语、带情绪的表达,容易被误分类。
工程解法
通过配置 意图示例 来做快速干预:
- 收集 bad case:从监控日志中捞出识别错误的 query
- 补充示例:在对应意图的配置中,把这些 query 加入"意图示例"
- 验证生效:重新测试,确认识别结果符合预期
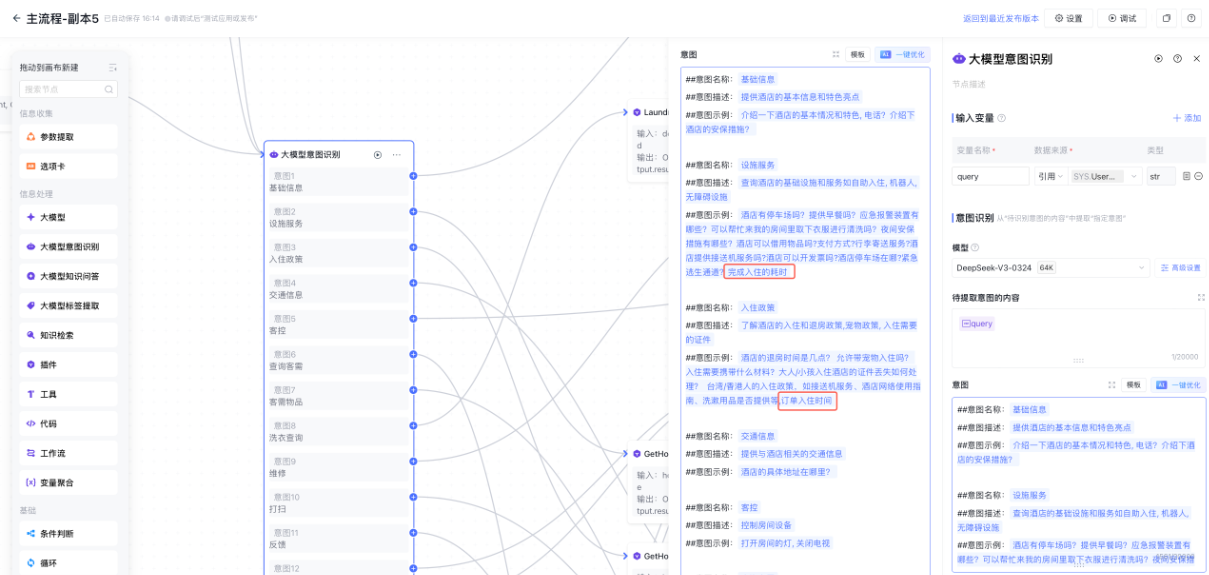
关键细节
- 意图示例不是越多越好,要选有代表性的、能覆盖边界情况的
- 如果某类表达确实模糊(既像 A 又像 B),可以考虑在工作流中加二次确认,而不是强行归类
5.5 提示词写得很清楚,但模型就是不遵循?
场景还原
提示词里明明写了"如果用户没有提供房间号,必须追问",但模型有时候会跳过追问,直接给一个模糊回复。
为什么会这样?
两个常见原因:
- 约束被淹没:提示词太长,关键约束和大量变量内容混在一起,模型"看不到"重点
- 变量内容干扰:当变量内容(如知识库检索结果)很长时,模型的注意力被分散
工程解法
- 结构化提示词:用清晰的分隔符(如
###、---)划分"规则区"和"内容区",规则区放前面 - 长变量后置:把较长的变量内容(如检索结果、历史对话)放到提示词最后,让关键约束更聚焦
- 单节点调试:逐个节点测试,定位到底是哪个节点没遵循约束

关键细节
- 如果某条规则特别重要,可以在提示词中重复强调(开头一次、结尾一次)
- 复杂逻辑不要全靠提示词,能用代码节点做的判断就用代码节点
第 6 步:监控与持续迭代
为什么重要: 上线不是终点,是起点。指标达标来自持续迭代。
6.1 监控看板必看指标
| 指标 | 说明 |
|---|---|
| 回复准确率 | 抽样评审 |
| 首 token / 全链路时延 | 体感"是否秒回" |
| 转人工率 | 区分主动 vs 系统触发 |
| 工具调用成功率 | 工单创建、客控下发等 |
| 低置信度占比 | 及 Top 触发原因 |
| Top 未命中问题 | 用于补知识/补意图 |
6.2 质检闭环节奏
| 周期 | 动作 |
|---|---|
| 每周 | 复盘转人工对话 → 归因 → 小步修复 |
| 每月 | 意图与工作流体检 → 合并/拆分意图、更新话术 |
6.3 排查利器:单节点调试
当效果不符合预期时,用单节点调试快速定位问题来源:
- 政策文档的限定条件是否写清楚?
- 拒答策略是否能稳定触发?
- 参数提取是否准确?
结果复盘
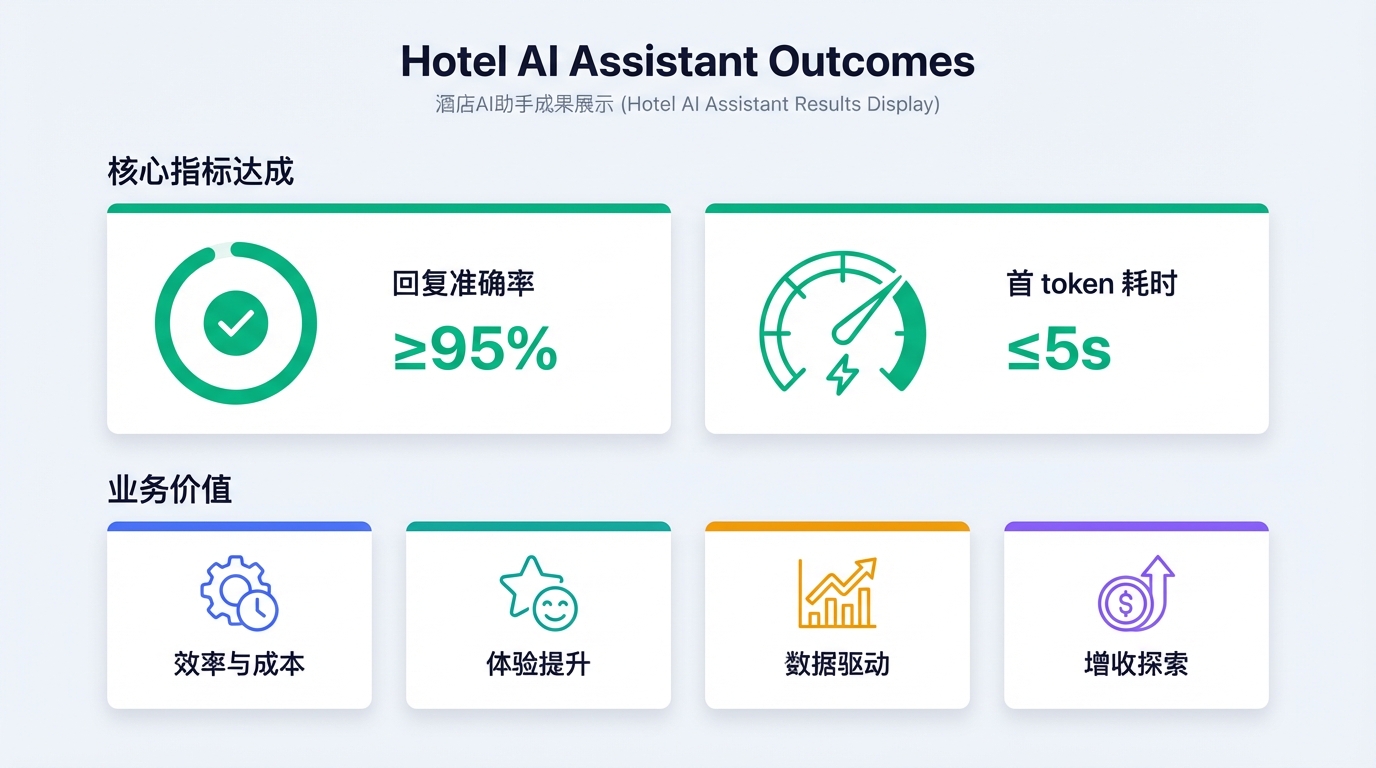
经过持续调优,项目达到了验收门槛:
| 指标 | 结果 |
|---|---|
| 智能客服回复准确率 | ≥95% ✅ |
| 首 token 耗时 | ≤5s ✅ |
在业务价值上,酒店行业普遍会从四个方向受益:
| 价值维度 | 说明 |
|---|---|
| 效率与成本 | 7×24 承接常见问询与客需,解放人力处理更复杂问题 |
| 体验提升 | 秒级响应 + 一站式服务减少等待与反复沟通 |
| 数据驱动 | 沉淀高频问题与偏好数据,反哺服务优化与运营 |
| 增收探索 | 通过周边推荐与服务订购,拓展非客房收入 |
常见问题(FAQ)
Q1: 为什么很多酒店智能客服"看起来能聊,但上线就翻车"?
最常见的原因是把"聊天能力"当成"交付能力"。上线需要把流程、权限、兜底与审计做成工程控制面,而不是让模型自由发挥。
Q2: 哪些场景不建议用 RAG?
可结构化查询的事实(酒店电话、地址、设施是否存在、入住时间等)优先走数据库/接口查询,避免生成式模型"说得像但不准确"。
Q3: 多意图 query 怎么处理最稳?
不要指望单意图流程能把多问题一次性处理好。更稳的做法是单独的"多意图"入口:拆分 → 分发到子工作流 → 汇总输出。
Q4: 怎么保证"中文问中文答、英文问英文答"?
比"在提示词里要求按语种回复"更稳的方式是:开始节点加语言判断,输出 output_language 变量,后续所有节点引用它;兜底话术建议人工翻译固定。
Q5: 如何避免模型对不存在的实体(房型/设施)胡编?
把"实体不存在要拒答/转人工"写成硬规则,并将约束放在提示词前部;同时用单节点调试验证拒答是否稳定触发。
Q6: 酒店场景的"写权限"怎么控才安全?
只读优先;写操作只保留在极少数动作(生成工单、下发客控),并加二次确认 + 审计留痕 + 异常回滚/转人工。
Q7: 从单工作流切换到标准模式麻烦吗?
Tencent Cloud ADP 支持一键切换。关键是提前规划好意图拆分策略,避免切换后意图命中率下降。
相关阅读

Hotel Guest Services

标准模式
AI customer service for hotel guests, addressing enquiries regarding guest requirements, room controls, and fundamental hotel information.
立即开始搭建
如需更多帮助,欢迎联系我们。