 首页
首页 产品
产品 资源
资源 专业解决方案
专业解决方案 定价
定价 公司
公司 找到我们
找到我们企业 AI Agent Token 成本优化实战指南
AI Agent 上线后 Token 账单远超预期?多数团队只算了"输入+输出",却忽略了系统提示词、对话历史和 RAG 检索注入等隐性开销。本文基于腾讯云 ADP 平台实践,提供意图路由、检索优化、分层模型三大降本策略。

摘要
AI Agent 上线后 Token 账单远超预期?多数团队只算了"输入+输出",却忽略了系统提示词、对话历史和 RAG 检索注入等隐性开销。本文基于腾讯云 ADP 平台实践,提供意图路由、检索优化、分层模型三大降本策略。
构建企业级 AI Agent — 腾讯云智能体开发平台,首月免费试用
本文涵盖:
- AI Agent 各环节的 Token 消耗构成与隐性成本
- 意图路由如何将简单请求从重链路中分流
- RAG 检索精度优化如何减少无效上下文注入
- 分层模型策略如何在保持质量的前提下降低推理成本
你将了解: 如何建立一套可观测、可量化的 Token 成本治理方法论。
为什么 Token 成本会失控
被忽视的隐性消耗
多数团队在预估 AI Agent 成本时,习惯用"单次调用的 Token 数 × 请求量"来计算。但在生产环境中,一次用户请求触发的 Token 消耗远不止表面看到的那些:
| 消耗环节 | 典型 Token 量 | 是否每次调用都会产生 |
|---|---|---|
| 用户原始输入 | 20-200 | 是 |
| 系统提示词 | 500-3,000 | 是,每次调用都携带 |
| 对话历史 | 第 N 轮 ≈ N × 单轮消耗 | 多轮场景累积 |
| RAG 检索结果 | 500-5,000 | 知识问答场景 |
| 模型输出 | 200-1,000 | 是 |
一个看似只消耗 200 Token 的用户提问,实际触发的完整链路可能消耗 3,000-8,000 Token。当日均请求量达到数万甚至数十万级别时,这个差距会被急剧放大。

三类典型成本问题
- 预算偏差:初始估算未考虑多轮累积、系统提示词、检索注入等开销,导致上线后账单大幅超出预期
- 成本不可观测:不知道 Token 主要消耗在哪些意图、哪些环节,优化无从下手
- 质量与成本的拉锯:降模型怕影响准确率,不降又控不住成本,团队陷入两难
Token 在 Agent 链路中的消耗结构
要优化成本,先要理解 Token 在 AI Agent 处理链路中是如何流动的。
一次请求的完整链路
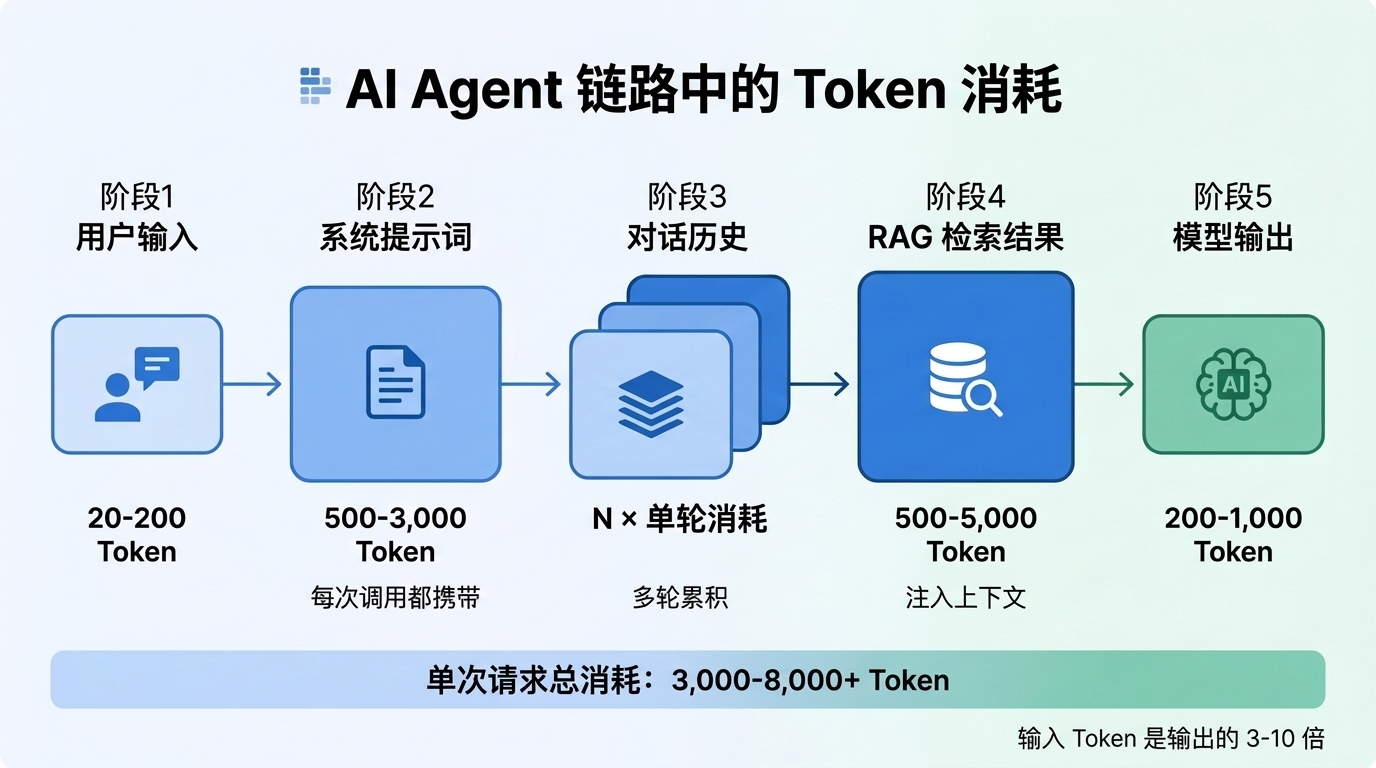
一个典型的企业 AI Agent 对一次用户请求的处理包含以下环节:
| 环节 | 作用 | Token 消耗特征 |
|---|---|---|
| 意图识别 | 判断用户请求属于哪个业务场景 | 输入:系统提示词 + 用户输入;输出:意图标签(200-500 Token) |
| 参数提取 | 从用户输入中抽取结构化参数 | 输入:提取规则 + 用户输入;输出:JSON 参数(100-300 Token) |
| 知识检索 | 从向量数据库检索相关文档片段 | 检索本身不消耗推理 Token,但检索结果注入上下文会增加后续调用的输入 Token |
| 响应生成 | 基于上下文生成最终回复 | 输入:系统提示词 + 对话历史 + 检索结果;输出:回复文本 |
| 质量校验(可选) | 检查回复准确性和合规性 | 额外一次模型调用,100-500 Token |
关键发现: 单次请求中,输入 Token 通常是输出 Token 的 3-10 倍。成本优化的核心在于减少输入端的冗余——特别是系统提示词和检索注入。
三项核心优化策略
策略一:意图路由——让简单请求走快速通道
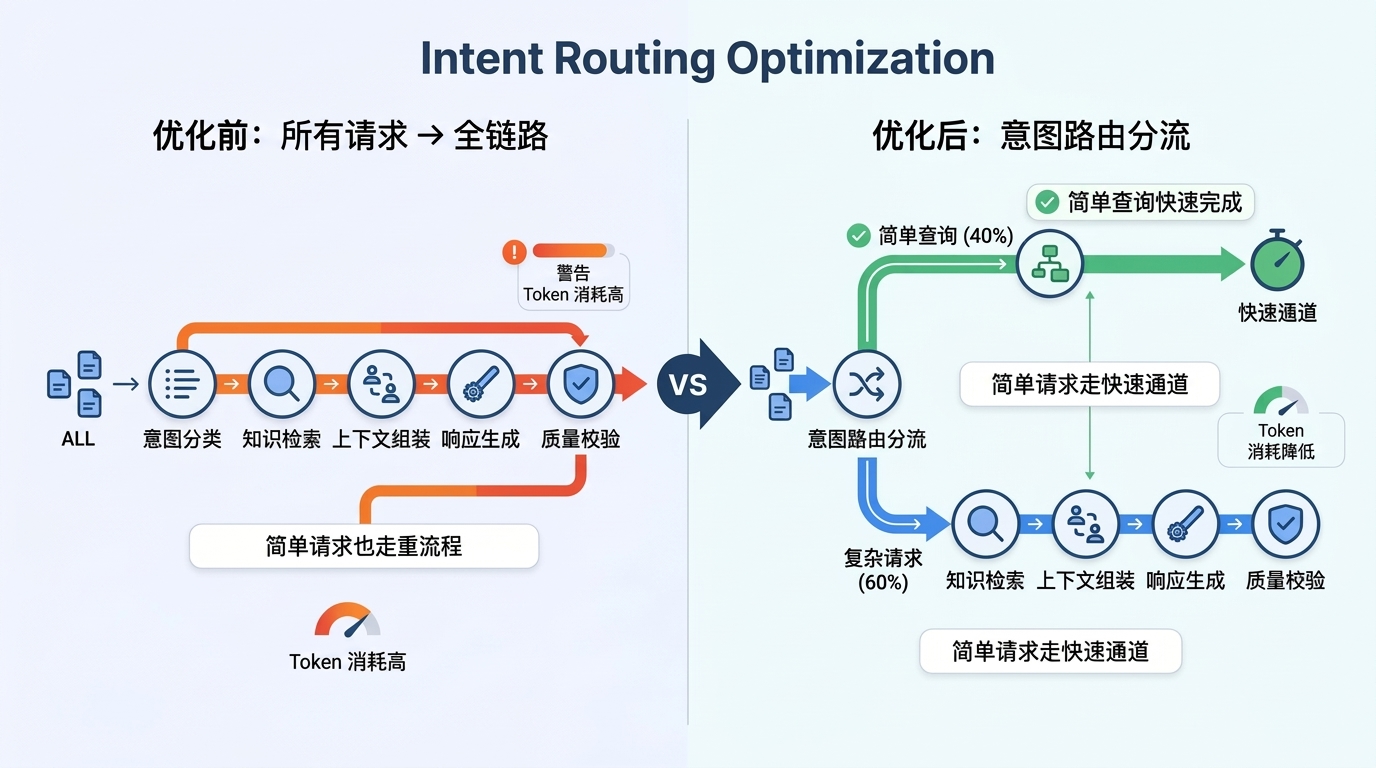
问题:许多 Agent 架构对所有请求一视同仁,无论用户问的是"我的订单到哪了"还是需要复杂推理的技术问题,都走完整的"意图分类 → 检索 → 生成 → 校验"链路。
优化方案:在请求进入完整链路之前,增加一个轻量级的意图分类步骤。
腾讯云 ADP 平台的意图识别引擎支持全局意图分类和参数回退机制:
- 轻量模型分类:用低成本模型进行意图分类,单次调用仅消耗 200-500 Token
- 分流路由:简单查询(状态查询、FAQ 等)直接调用工具或返回固定话术,不进入完整链路
- 参数回退:当用户输入缺少必要参数时,自动追问补全,而非盲目调用检索和生成
效果原理:一次完整的"检索 + 生成"链路消耗 3,000-8,000 Token。如果 30-50% 的请求属于简单查询,通过意图路由分流后,这部分请求的 Token 消耗可降低 80% 以上。即使意图分类本身消耗 300 Token,只要能拦截 10% 的简单请求,投入即可收回。
策略二:RAG 检索精度优化——减少无效上下文注入
RAG 是企业 AI Agent 的核心能力,但也是 Token 消耗的最大变量。检索返回的文档片段越多、越长,注入到模型上下文的 Token 就越多,成本随之线性增长。
优化手段对比:
| 检索参数 | 常见默认值 | 优化建议 | Token 影响 |
|---|---|---|---|
| 返回文档数量 | Top 10 | Top 3-5 | 减少 50-70% 上下文注入 |
| 单文档最大长度 | 1,000 Token | 500 Token | 减少 50% 单篇注入 |
| 重排序 | 未启用 | 启用 | 精准度提升,同等精度下可减少返回数量 |
| 文档分块策略 | 固定 500 字切分 | 语义分块(200-300 Token) | 减少无效信息注入 |
具体做法:
- 小分块 + 重排序:将文档分成更小的语义块(200-300 Token),先检索 Top 10 候选,再用重排序模型精选 Top 3-5 注入上下文。小分块颗粒度更细,重排序保证精度不降
- 元数据过滤前置:在向量检索前,先通过元数据(部门、文档类型、时间范围)过滤候选集,缩小检索范围
- 查询改写:用轻量模型将用户的口语化查询改写为精确检索词,提高首次检索命中率
腾讯云 ADP 的知识检索模块支持 28+ 文档格式、单文件 200MB,内置重排序能力,可以在平台层面直接配置上述参数。
策略三:分层模型——不同任务用不同模型
这是降本效果最显著的策略。核心思路:并非所有任务都需要最强大(也最昂贵)的模型。
| 任务类型 | 复杂度 | 推荐模型层级 | 成本参考 |
|---|---|---|---|
| 意图分类 | 低 | 轻量模型(如 GPT-4o-mini) | 输入 $0.15/MTok |
| 参数提取 | 低 | 轻量模型 | 输入 $0.15/MTok |
| 简单问答 | 中 | 中等模型(如 Claude Haiku) | 输入 $1.00/MTok |
| 复杂推理 | 高 | 旗舰模型(如 Claude Sonnet) | 输入 $3.00/MTok |
关键原则:不是凭直觉选模型,而是用评测数据做决策。腾讯云 ADP 的应用评测体系提供"对比评测"功能——对同一批测试用例分别用旗舰模型和轻量模型生成结果,量化比较质量差异。如果轻量模型的准确率仅比旗舰模型低 2-3%,但成本低 10 倍,选择就很清晰。
混合成本示例:
假设日均 10 万次请求,分布如下:
- 简单查询 40% → 轻量模型:40,000 × $0.001 = $40
- 标准问答 45% → 中等模型:45,000 × $0.005 = $225
- 复杂推理 15% → 旗舰模型:15,000 × $0.030 = $450
总成本:$715/天
vs 全部使用旗舰模型: 100,000 × $0.030 = $3,000/天
节省约 76%
实际效果演示
以一个"运单状态查询"场景为例,展示优化前后的 Token 消耗差异。
用户输入:"帮我查一下运单 SF1234567890 到了哪里"
优化前(全链路处理,单一旗舰模型)
| 步骤 | 模型 | 输入 Token | 输出 Token |
|---|---|---|---|
| 意图分类 | 旗舰模型 | 1,200 | 150 |
| 参数提取 | 旗舰模型 | 1,500 | 80 |
| 知识检索 | 嵌入模型 | 300 | — |
| 上下文组装 | — | 3,500(检索结果注入) | — |
| 响应生成 | 旗舰模型 | 5,200 | 200 |
| 合计 | 约 11,700 | 约 430 |
优化后(意图路由 + 分层模型 + 检索精简)
| 步骤 | 模型 | 输入 Token | 输出 Token |
|---|---|---|---|
| 意图分类 | 轻量模型 | 800 | 120 |
| 参数提取 | 轻量模型 | 1,000 | 60 |
| 结构化查询 | API 调用(无模型) | — | — |
| 响应生成 | 中等模型 | 1,200 | 150 |
| 合计 | 约 3,000 | 约 330 |
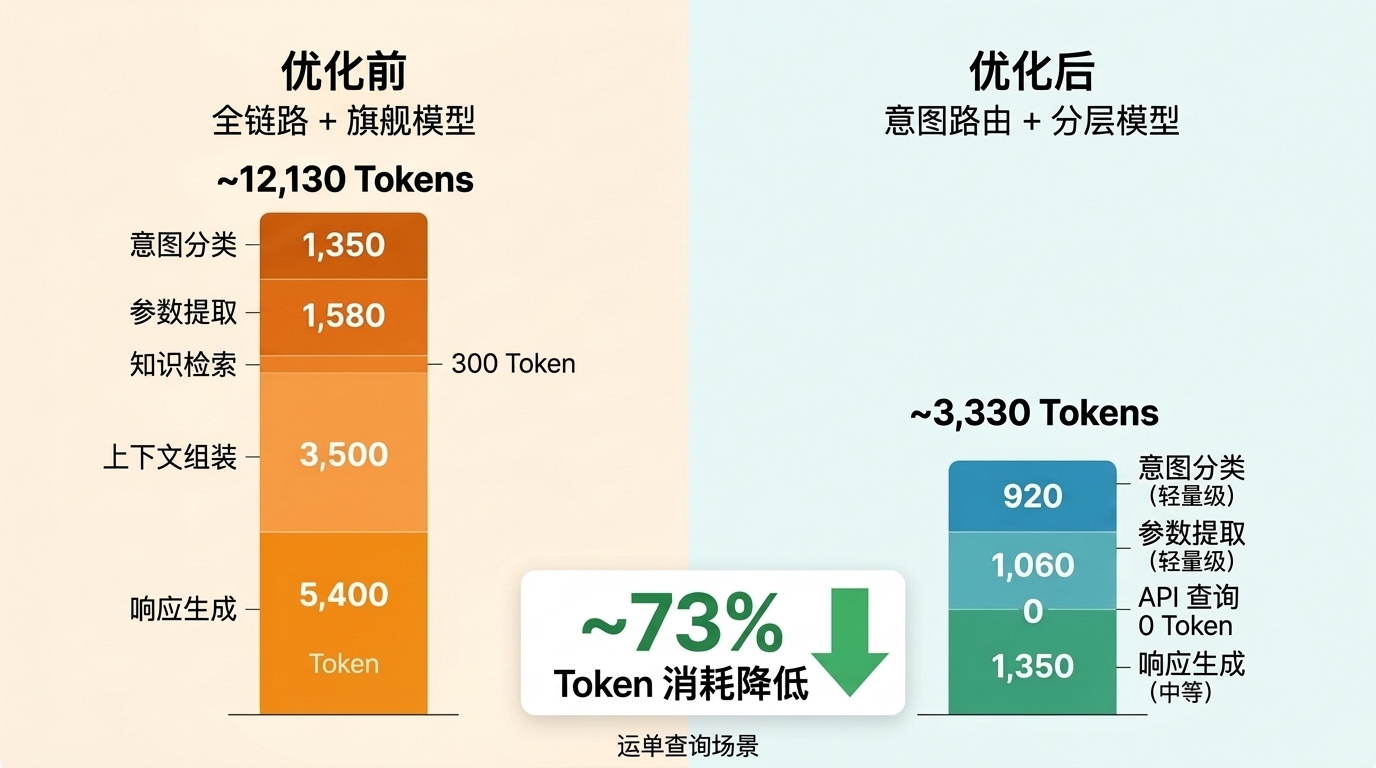
"运单状态查询"属于简单查询——意图路由识别后直接走结构化 API 查询,跳过了 RAG 检索环节,Token 消耗大幅减少。
可量化的优化框架
Token 成本优化不是一次性动作,而是需要持续监控和迭代的过程。以下是建议的治理框架:
成本观测三维度
| 维度 | 监控指标 | 优化动作 |
|---|---|---|
| 意图维度 | 各意图的平均 Token 消耗、请求占比 | 识别 Top 10 高消耗意图,优先优化 |
| 环节维度 | 各环节(分类/检索/生成)的 Token 占比 | 定位消耗热点,针对性调整 |
| 模型维度 | 各模型的调用次数、成功率、成本占比 | 验证分层策略效果,持续调整模型分配 |
实施步骤
- 建立基线:上线前统计各意图的 Token 消耗基线数据
- 意图分流:优先部署意图路由,将简单请求从重链路中分流
- 检索调优:调整分块策略和 Top-K 参数,用重排序替代"返回更多文档"
- 模型分层:用对比评测验证轻量模型在各意图上的表现,逐步替换
- 持续监控:建立 Token 消耗看板,按意图/环节/模型三维度追踪
行业适用性
Token 成本优化适用于所有部署了 AI Agent 的企业场景,尤其是以下特征的场景:
| 场景特征 | 优化重点 | 预期效果 |
|---|---|---|
| 请求量大、简单查询占比高 | 意图路由分流 | 简单查询 Token 消耗降低 80%+ |
| 知识库文档多、检索频繁 | RAG 检索精度优化 | 上下文注入 Token 减少 50-70% |
| 任务类型多、复杂度差异大 | 分层模型策略 | 综合推理成本降低 50-70% |
| 多轮对话频繁 | 对话历史压缩 + 意图路由 | 累积 Token 消耗显著下降 |
常见问题
Q1: 意图路由本身消耗 Token,是否得不偿失?
不会。意图分类用轻量模型,单次仅消耗 200-500 Token。而一次完整的"检索 + 生成"链路消耗 3,000-8,000 Token。只要路由拦截 10% 以上的简单请求,投入即可回本。
Q2: 降模型会不会导致回复质量下降?
关键是用数据而非直觉做决策。建议用 ADP 平台的对比评测功能,对每个意图分别验证轻量模型的表现。如果某个意图降级后准确率下降超过 5%,该意图继续使用旗舰模型。
Q3: RAG 返回 Top 3 和 Top 10,质量差距大吗?
取决于分块策略和重排序质量。实践中,Top 3 + 重排序的准确率通常与 Top 10(无重排序)持平甚至更高——因为减少了噪声信息干扰。前提是分块粒度合理(200-300 Token 的语义分块)。
Q4: 什么量级的 Token 消耗需要开始关注成本优化?
如果日均 Token 消耗超过 100 万(月度推理成本约 $3,000-15,000),就值得系统性优化。日均 1,000 万以上,优化是刚需。
Q5: 如何建立 Token 成本的持续监控?
建议按"意图 → 环节 → 模型"三维度建立消耗看板,重点关注 Top 10 高消耗意图、各意图的消耗趋势、以及模型调用次数与成功率的交叉分析。
Q6: 除了推理 Token,还有哪些隐性成本?
需要关注:知识库维护成本(文档更新、分块重建、索引刷新)、人工审核成本(边缘场景的人工介入)、以及延迟成本(链路过长导致的用户体验下降)。
结论:Token 优化的核心是精准
企业 AI Agent 的成本优化,本质不是"省钱"而是"精准"——把每一颗 Token 花在刀刃上。
三个关键动作:
- 精准路由:用轻量模型做意图分类,让简单请求走快速通道
- 精准检索:小分块 + 重排序,减少噪声上下文注入
- 精准匹配:不同复杂度的任务用不同等级的模型,用评测数据做决策
这套方法论的最大价值不在于某个单项技巧,而在于建立一套可观测、可量化、可持续迭代的成本治理框架。
准备开始了?
→ 试试 腾讯云智能体开发平台 — 知识库、工作流、大模型能力开箱即用,内置应用评测与成本监控,快速构建你的行业 AI Agent。
本文是企业 AI Agent 系列的一部分。相关阅读:
立即开始搭建
如需更多帮助,欢迎联系我们。