Hotel AI Service Assistant in Practice
A real-world hotel AI agent showcase: define scope, connect knowledge and systems, design workflows, add guardrails, and ship with monitoring.

Summary
A leading hotel chain launched a "24/7 Digital Concierge"—an AI-powered service assistant within their mobile app. The hard targets: response accuracy ≥95%, time to first token ≤5s.
This article walks through the entire implementation, including:
- Why we switched from "single workflow mode" to "standard mode"
- Engineering solutions for multi-intent queries, language switching, and hallucination prevention
- When to use RAG vs. structured queries

This article contains no company names, customer information, or sensitive scale data—only processes, methodologies, and practical paths.
Prerequisites
Before you start, ensure you have:
- [ ] Access to an agent building platform (this article uses Tencent Cloud ADP as reference)
- [ ] Integration permissions for hotel business systems (ticketing, PMS, IoT controls, etc.)
- [ ] A defined list of business scenarios and intents
- [ ] Success metrics defined (accuracy, latency, human handoff rate)
Time estimate: ~4-6 weeks from kickoff to first release; continuous tuning throughout operations
Step 1: Define Scope and Success Metrics
Why it matters: The #1 reason hotel AI assistants fail isn't model capability—it's scope creep. Don't treat "smart assistant" as "omniscient concierge."
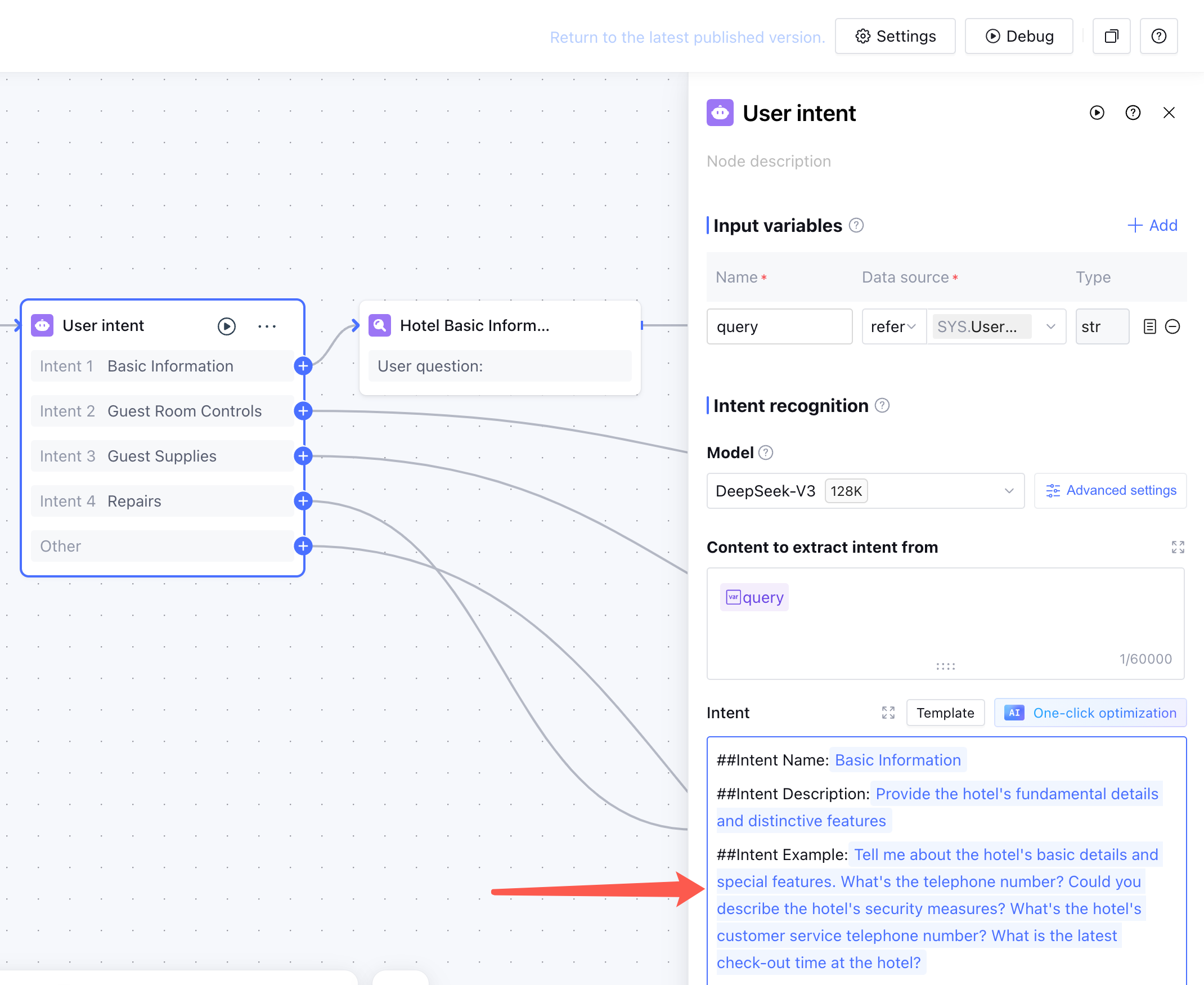
1.1 Scope Definition Framework
Before writing any prompts, answer these questions clearly:
| Question | Bad Answer | Good Answer |
|---|---|---|
| What queries will the Agent handle? | "Guest questions" | "Item delivery, hotel info, facility queries, Wi-Fi/invoicing, nearby recommendations, room controls" |
| What's the accuracy requirement? | "As accurate as possible" | "Response accuracy ≥95%, edge cases escalate to human" |
| What's the latency requirement? | "Fast" | "Time to first token ≤5s" |
| What systems need integration? | "Hotel systems" | "Ticketing (write), PMS (read), IoT controls (write), Maps/Weather API (read)" |
| What's out of scope? | (blank) | "Payment disputes, privacy/security, escalated complaints, legal/medical advice" |
1.2 In Scope
The assistant prioritizes "standardized, high-frequency, verifiable" capabilities:
| Scenario | Description | Key Action |
|---|---|---|
| Item Delivery | Water, amenities, etc. | Intent recognition → Parameter extraction → Create ticket → Dispatch |
| Hotel Information | Phone, address, check-in time, policies | Structured data query (not RAG) |
| Facilities | Parking, restaurant, gym, meeting rooms | Database query |
| Touchpoint Services | Wi-Fi, invoicing, breakfast, laundry | Query / redirect to third-party |
| Nearby Recommendations | Weather, transportation, attractions, dining | Maps/Weather API calls |
| Room Controls | Lights/curtains/AC/TV | Parameter extraction → IoT dispatch |
1.3 Out of Scope
Anything involving sensitive information, subjective judgment, or uncontrollable commitments defaults to human handoff:
- Payment disputes, refund conflicts, billing anomalies
- Privacy/security (identity verification, sensitive info changes)
- Escalated complaints / conflict situations
- Legal/medical high-risk consultations
- Any "write to core system" action (default read-only; writes require confirmation + audit trail)
1.4 Success Metrics
Define these before launch—not after:
| Metric | Target | Notes |
|---|---|---|
| Response Accuracy | ≥95% | Define sampling criteria and "correct" judgment standards |
| Time to First Token | ≤5s | Primary driver of "instant response" perception |
| Human Handoff Rate | Significant reduction | Distinguish "user requested human" vs. "system-triggered escalation" |
| Satisfaction | Improvement | Recommend segmenting by channel, hotel type, time period |
Step 2: Understand Business Pain Points
Why it matters: Without understanding pain points, you can't design the right solution.
Hotel customer service has a classic contradiction:
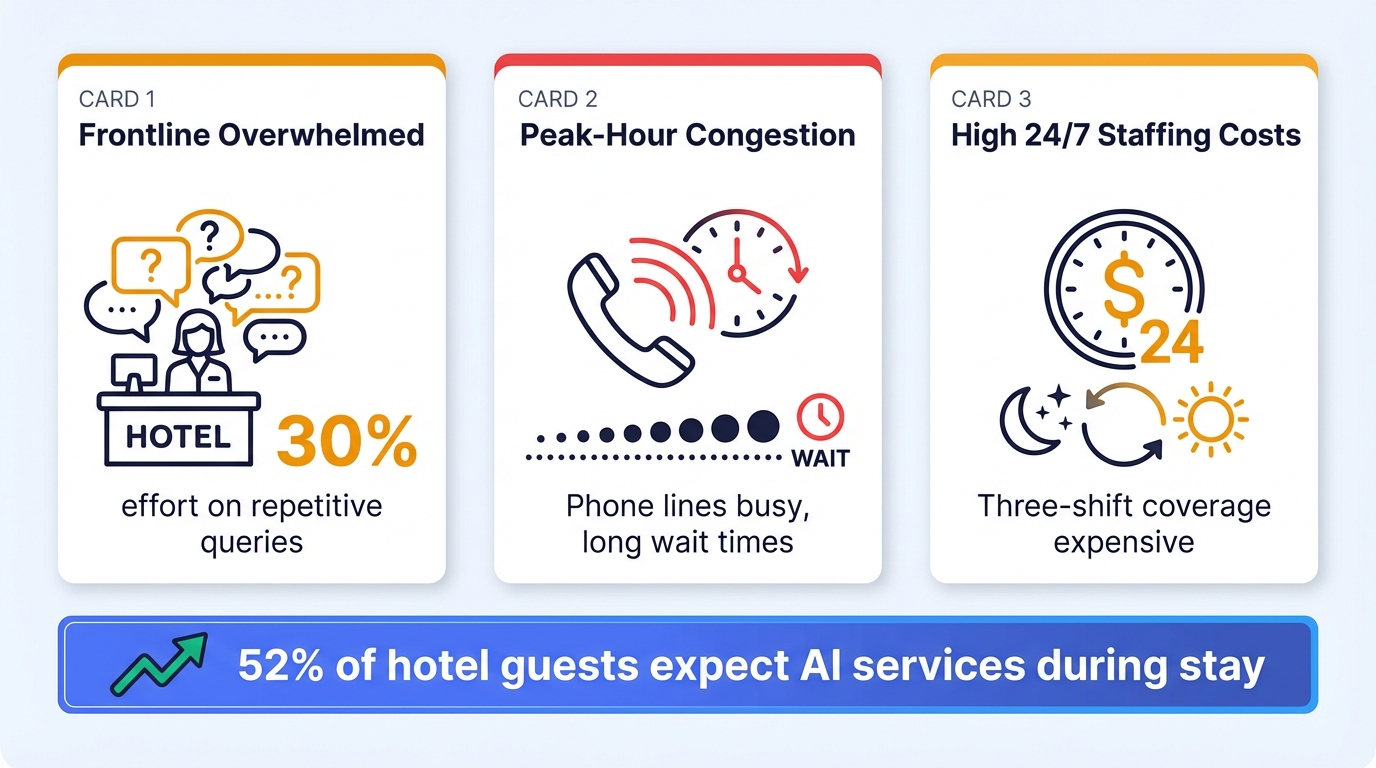
| Pain Point | Manifestation |
|---|---|
| Frontline overwhelmed by repetitive queries | Front desk staff spend over 30% of their effort on repetitive questions ("Is the pool open?" "Send me a toothbrush") |
| Peak-hour channel congestion | Phone lines busy, guests wait too long, frustration builds |
| High 24/7 staffing costs | Three-shift coverage is expensive; low overnight volume means poor utilization |
Industry data shows: 52% of hotel guests expect AI services during their stay. This isn't "nice to have"—it's "fall behind without it."
Step 3: Choose the Application Mode
Why it matters: Wrong mode choice = everything downstream goes wrong.
3.1 Three Modes Compared
| Mode | Use Case | Fit for This Project |
|---|---|---|
| Single Workflow Mode | Few intents (<20), simple flows | ✅ Early stage |
| Standard Mode | Many intents, multiple workflows collaborating | ✅ Mid-to-late stage switch |
| MultiAgent Mode | Complex multi-role collaboration | ❌ Not needed here |
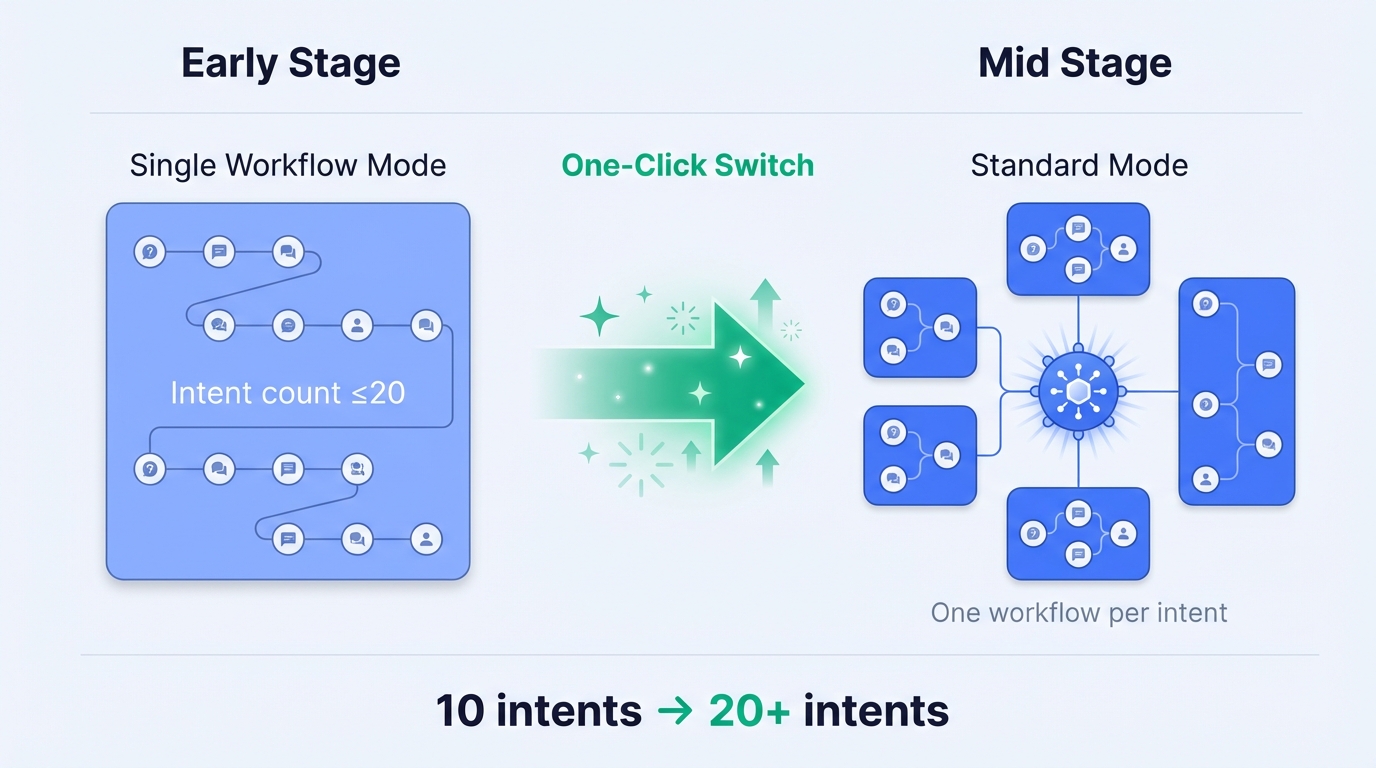
3.2 Mode Evolution in This Project
Early Stage: Single Workflow Mode
- No documentation or FAQ; workflow-driven
- ~10 intents, tightly scoped
- Two scenario types: 1. Intent recognition → Plugin query → LLM summarizes response 2. Intent recognition → Parameter extraction → Plugin creates order
Mid Stage: Switch to Standard Mode
- Requirements changed, intent count increased
- Intent recognition node has 20-intent limit; single workflow couldn't handle it
- Solution: Switch to standard mode, one workflow per intent
- Platform capability: One-click switch from single workflow to standard mode
Step 4: Design System Architecture
Why it matters: Architecture determines which problems you can solve and which become pitfalls.
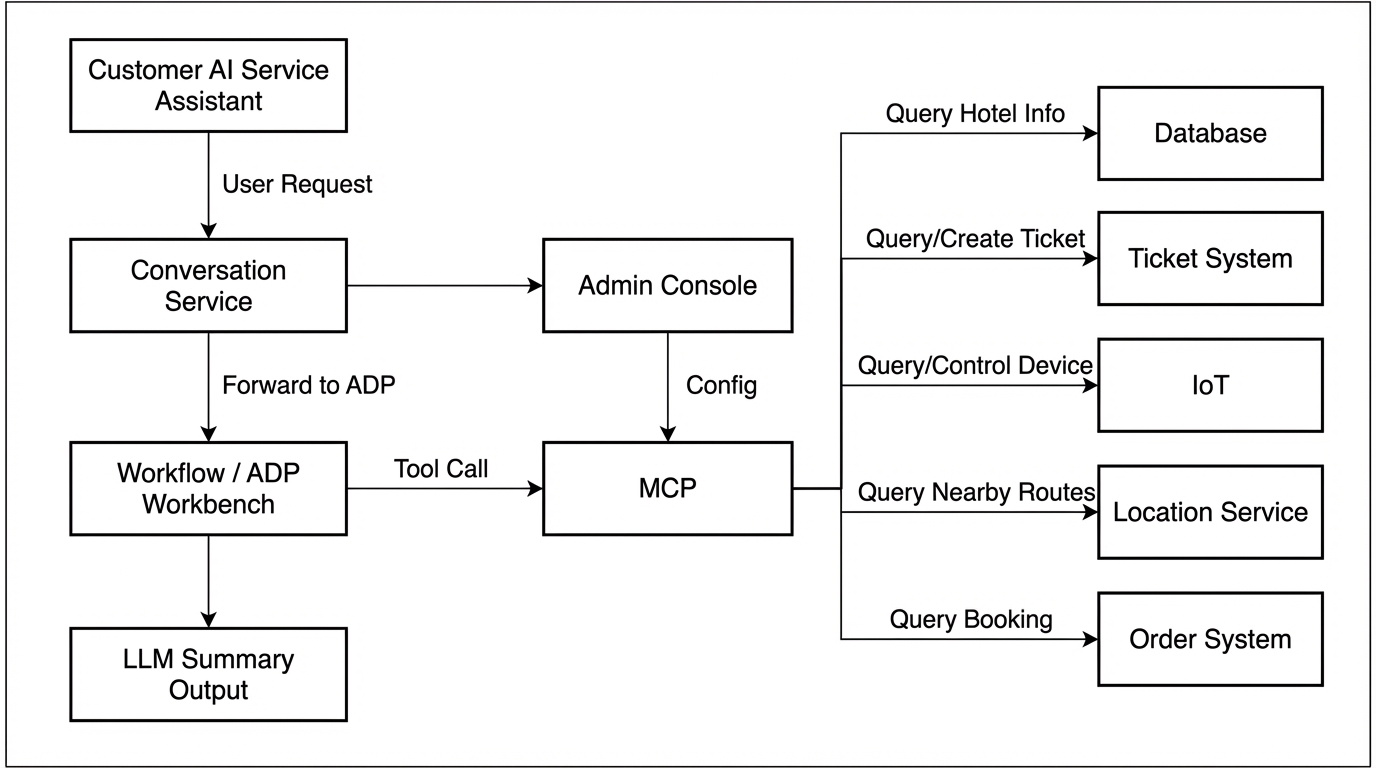
4.1 Overall Architecture
4.2 "RAG or Not" Decision Framework
This is one of the most critical engineering decisions:
| Scenario Type | Typical Question | Recommended Path | Reason |
|---|---|---|---|
| Structured Facts | Check-in time, pet policy | Tool query (DB/API) | Avoid "sounds right but isn't accurate" |
| Action Requests | Send water, turn on AC | Workflow + Parameter extraction + Tool | Requires precise parameters and execution |
| Nearby Info | How to get to airport | Workflow + Maps API | Time-sensitive results |
| Policy Interpretation | Minor guest policy details | RAG + Strong refusal constraints | Requires understanding long documents |
Core principle: If it can be queried structurally, don't use RAG.
For detailed guidance on RAG cold-start and knowledge base setup, see How Enterprises Build AI Agents: From PoC to Production.
4.3 System Integration Checklist
| System | Purpose | Permission |
|---|---|---|
| Ticketing System | Item delivery, repairs, in-stay requests | Write |
| PMS | Booking/check-in data | Read |
| Hotel Info Database | Hotel info, facility info | Read |
| IoT Controls | Lights/curtains/AC, etc. | Write |
| Third-party Connectors | Wi-Fi, invoicing, laundry | Read/Redirect |
| Maps/Weather | Nearby recommendations, routes | Read |
Permission strategy: Read-only by default; write operations limited to minimum set, with confirmation + audit trail.
Step 5: Real-World Tuning Experience
Why it matters: These issues aren't "might encounter"—they're "will definitely encounter." Below are lessons learned from the project, many discovered only after hitting problems.
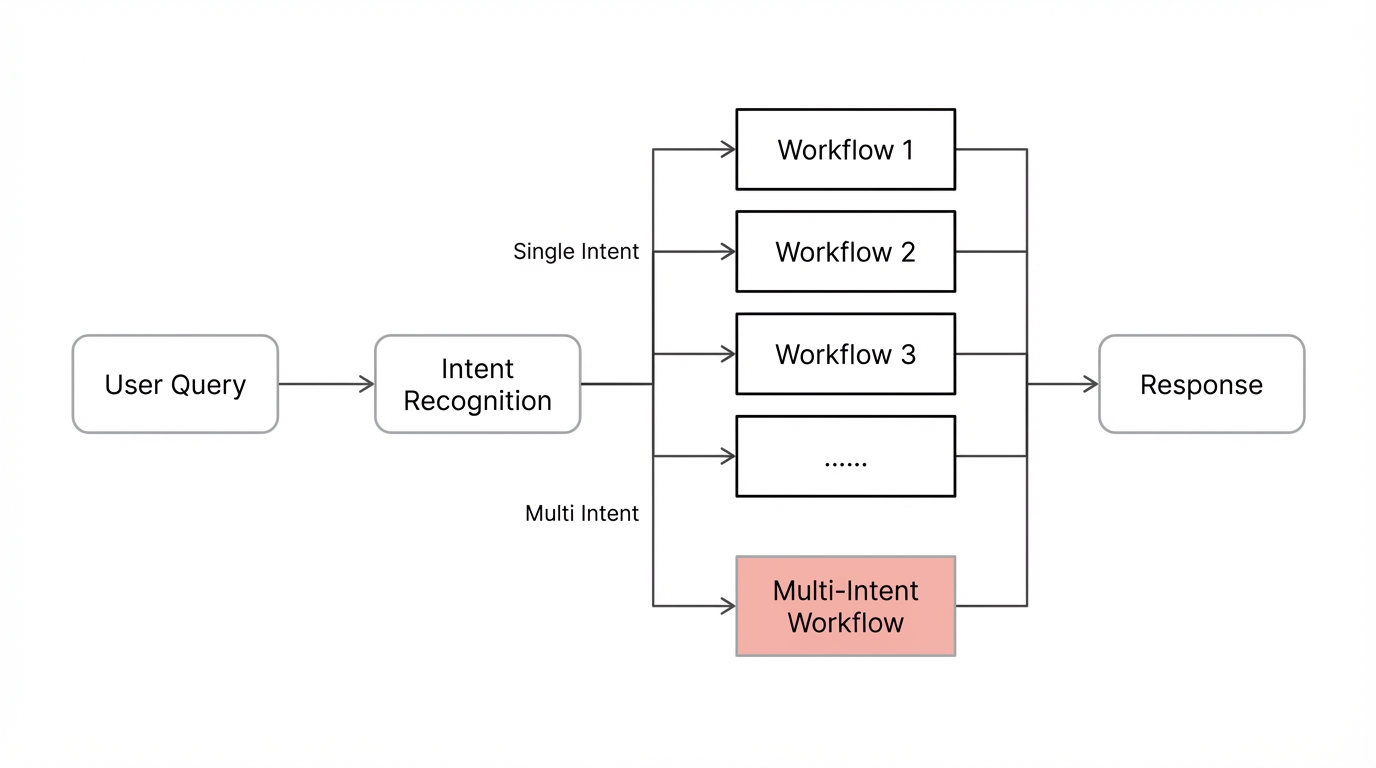
5.1 Single Query Contains Multiple Intents—How to Answer All?
Scenario
A guest sends: "Please fix my toilet, also how much is parking, and I want to switch to a king bed room."
This query contains three independent intents: repair request, facility inquiry, room type change. But in standard intent recognition, the system only matches one workflow (usually the first or highest confidence), ignoring the rest.
Why This Happens
Most Agent frameworks use "single-select" intent logic: one query → one intent → one workflow. Fine for single-intent scenarios, but hotel guests often "ask everything at once."
Engineering Solution
We added a "multi-intent entry workflow" specifically for this:
- Recognize multi-intent: Explicitly include multi-intent examples in workflow description (e.g., "repair + inquiry + room change"), emphasizing "when multiple intents detected, prioritize this workflow"
- Split intents: Use code node to split query into intent array, e.g.,
["fix toilet", "parking fee", "switch to king bed"] - Loop dispatch: Iterate array, call main flow for each, which routes to corresponding sub-workflows
- Merge output: Collect responses from sub-workflows, concatenate into one complete answer
Key Details
- Use a more stable intent model version (switching to
youtu-intent-proimproved results) - Multi-intent workflow priority must be higher than single-intent workflows, or it gets "stolen"
5.2 Multilingual Scenario—How to Ensure "Chinese In, Chinese Out"?
Scenario
Hotel guests come from different countries—some ask in Chinese, some in English. Expectation: reply in whatever language they used.
Initial approach: add "please reply in the user's input language" to prompts. Single-turn tests passed, but multi-turn conversations started mixing languages, sometimes completely mismatched.
Why This Happens
Prompt constraints get "diluted" in multi-turn context. As conversation history grows and variables multiply, model compliance with language constraints drops. Not the model "disobeying"—the constraint signal gets drowned in long context.
Engineering Solution
Turn language detection from "soft constraint" into "hard variable":
- Language detection node: Add an LLM node at workflow start that only detects query language, outputs
output_languagevariable (zh/en/ja, etc.) - Global reference: All subsequent response nodes and parameter extraction nodes reference
output_language, with explicit "reply in {{output_language}}" in prompts - Fixed phrase library: Fallback responses, refusal phrases, confirmation phrases—don't let model translate on the fly. Pre-translate manually, call appropriate version by language variable !language.png Key Details
- Parameter extraction node's follow-up prompts also need multilingual configuration, or you get "Chinese question → English follow-up" disconnect
- Language detection node prompt should be minimal—do one thing only, avoid introducing uncertainty
5.3 User Asks About Non-Existent Entity—How to Prevent Hallucination?
Scenario
Guest asks: "How much is your ocean view suite?" But this hotel has no "ocean view suite."
Expected answer: "Sorry, we don't currently have an ocean view suite. You might consider our city view king room or deluxe twin room."
Actual answer: "Ocean view suite is 1,280 per night, includes breakfast for two, with stunning ocean views..."—completely fabricated.
Why This Happens
LLM "hallucination" is fundamentally generating "plausible-looking" content based on language patterns when lacking factual constraints. When knowledge base or database returns empty, without explicit refusal instructions, the model tends to "complete" an answer.
Engineering Solution
- Explicit refusal rules: Add hard constraint to prompts—"If query result is empty or entity doesn't exist, must clearly inform user, must not fabricate information"
- Front-load constraints: Put refusal rules at prompt front or use special markers for emphasis. Don't bury them after long variable content. Experience shows compliance drops when key constraints are at prompt end
- Single-node debugging: Use single-node debug feature to specifically test "non-existent entity" cases, verify refusal triggers reliably
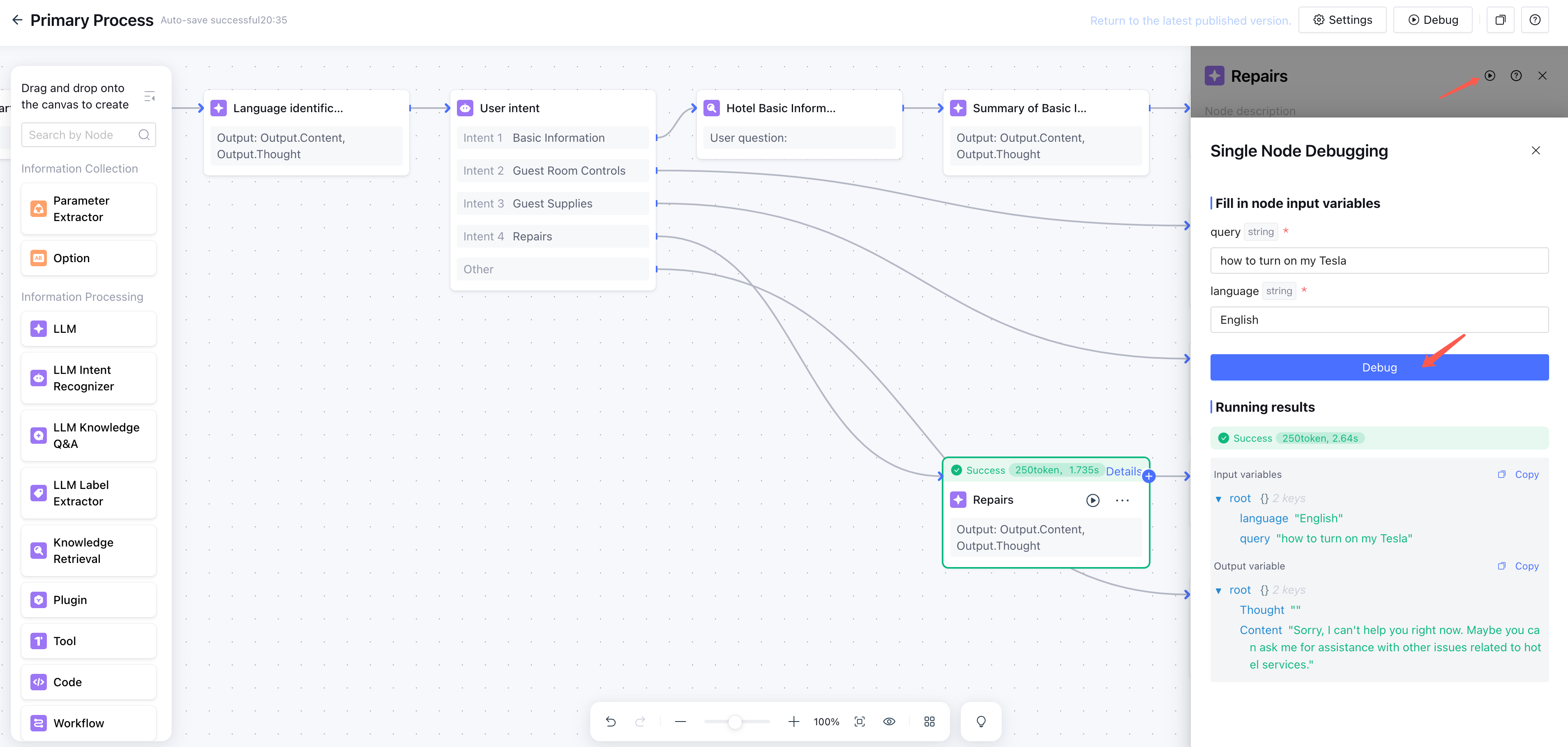
Key Details
- If certain policies have conditions (e.g., "mainland ID only"), write those conditions into knowledge documents, not just prompt constraints
- After refusal, provide alternatives ("No A, but we have B and C"), not just "we don't have that"
5.4 Intent Recognition Keeps Getting It Wrong—How to Intervene Quickly?
Scenario
Guest says "The AC is too cold," expecting to hit "room control" intent (raise temperature), but system recognized it as "complaint" intent, triggering human handoff.
Many similar cases: user expressions vary wildly, and when they don't match training data distribution, intent recognition errors occur.
Why This Happens
Intent recognition models are trained on limited samples and can't cover all real expressions. Especially colloquial, subject-omitting, emotional expressions get misclassified easily.
Engineering Solution
Use intent examples for quick intervention:
- Collect bad cases: Pull misrecognized queries from monitoring logs
- Add examples: Add these queries to "intent examples" in the corresponding intent configuration
- Verify effectiveness: Retest, confirm recognition matches expectations
Key Details
- More intent examples isn't always better—choose representative ones that cover edge cases
- If certain expressions are genuinely ambiguous (could be A or B), consider adding secondary confirmation in workflow rather than forcing classification
5.5 Prompt Is Crystal Clear, But Model Doesn't Follow?
Scenario
Prompt clearly states "if user doesn't provide room number, must ask for it," but model sometimes skips the follow-up and gives a vague response.
Why This Happens
Two common reasons:
- Constraint buried: Prompt too long, key constraints mixed with lots of variable content, model "can't see" the important parts
- Variable content interference: When variable content (like knowledge base retrieval results) is long, model attention gets dispersed
Engineering Solution
- Structure prompts: Use clear separators (
###,---) to divide "rules section" and "content section," rules section first - Long variables at end: Put longer variable content (retrieval results, conversation history) at prompt end, keeping key constraints focused
- Single-node debugging: Test node by node to locate which one isn't following constraints
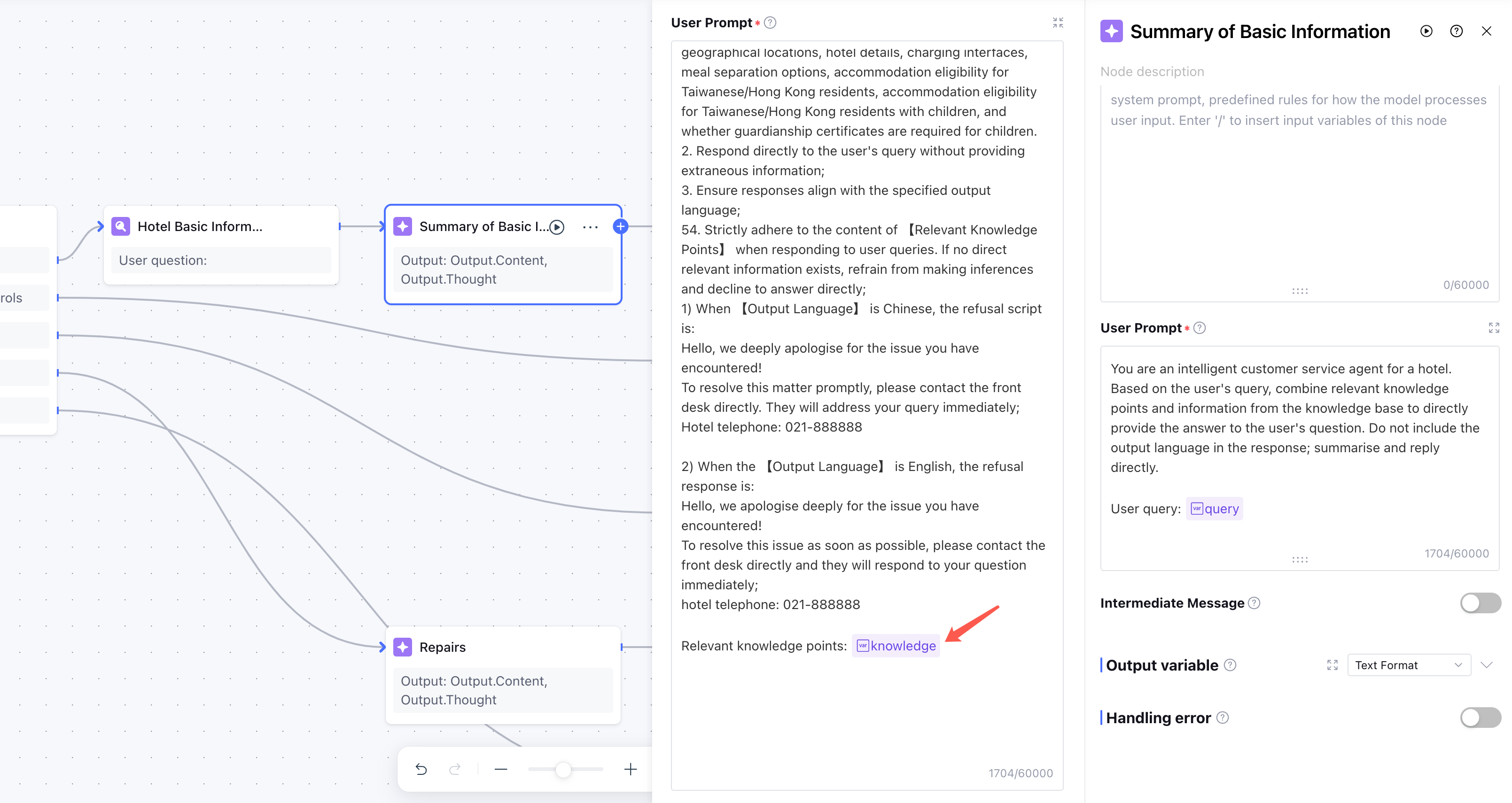
Key Details
- If a rule is especially important, repeat it in prompts (once at start, once at end)
- Don't rely entirely on prompts for complex logic—use code nodes for judgments when possible
Step 6: Monitoring and Continuous Iteration
Why it matters: Launch isn't the end—it's the beginning. Hitting metrics comes from continuous iteration.
6.1 Must-Watch Dashboard Metrics
| Metric | Description |
|---|---|
| Response Accuracy | Sampled review |
| First Token / End-to-end Latency | "Instant response" perception |
| Human Handoff Rate | Distinguish user-initiated vs. system-triggered |
| Tool Call Success Rate | Ticket creation, IoT dispatch, etc. |
| Low Confidence Ratio | And top trigger reasons |
| Top Unmatched Questions | For adding knowledge/intents |
6.2 Quality Review Cadence
| Cycle | Action |
|---|---|
| Weekly | Review human handoff conversations → Root cause → Quick fixes |
| Monthly | Intent and workflow health check → Merge/split intents, update phrases |
6.3 Debugging Power Tool: Single-Node Debug
When results don't meet expectations, use single-node debugging to quickly locate the source:
- Are policy document conditions written clearly?
- Does refusal strategy trigger reliably?
- Is parameter extraction accurate?
Results Review
After continuous tuning, the project met acceptance criteria:
| Metric | Result |
|---|---|
| AI Response Accuracy | ≥95% ✅ |
| Time to First Token | ≤5s ✅ |
On business value, hotels generally benefit in four dimensions:
| Value Dimension | Description |
|---|---|
| Efficiency & Cost | 24/7 handling of common inquiries and requests, freeing staff for complex issues |
| Experience Improvement | Instant response + one-stop service reduces waiting and back-and-forth |
| Data-Driven | Accumulate high-frequency questions and preference data, feed back into service optimization |
| Revenue Exploration | Nearby recommendations and service bookings expand non-room revenue |

FAQ
Q1: Why do many hotel AI assistants "seem conversational but fail at launch"?
Most common reason: treating "chat capability" as "delivery capability." Launch requires engineering processes, permissions, fallbacks, and audit into a control plane—not letting the model freestyle.
Q2: Which scenarios shouldn't use RAG?
Structurally queryable facts (hotel phone, address, facility existence, check-in time) should go through database/API queries first, avoiding generative models "sounding right but being wrong."
Q3: What's the most stable way to handle multi-intent queries?
Don't expect single-intent flows to handle multiple questions at once. More stable: dedicated "multi-intent" entry → split → dispatch to sub-workflows → aggregate output.
Q4: How to ensure "Chinese in, Chinese out; English in, English out"?
More stable than "asking in prompts to reply in user's language": add language detection at start node, output output_language variable, all subsequent nodes reference it; fallback phrases should be human-translated and fixed.
Q5: How to prevent model from fabricating non-existent entities (room types/facilities)?
Write "entity doesn't exist must refuse/escalate" as hard rule, place constraint at prompt front; also use single-node debugging to verify refusal triggers reliably.
Q6: How to safely control "write permissions" in hotel scenarios?
Read-only by default; write operations only for minimal actions (create ticket, dispatch IoT), with confirmation + audit trail + anomaly rollback/human escalation.
Q7: Is switching from single workflow to standard mode difficult?
Tencent Cloud ADP supports one-click switch. Key is planning intent splitting strategy in advance to avoid recognition rate drops after switching.
Related Reading

Hotel Guest Services

Standard
AI customer service for hotel guests, addressing enquiries regarding guest requirements, room controls, and fundamental hotel information.
Start building today
If you need more support, please contact us